介绍
《Swift 进阶》对一本书来说是一个很大胆的标题,所以我想我们应该先解释一下它意味着什么。
当我们开始本书第一版的写作的时候,Swift 才刚刚一岁。我们推测这门语言会在进入第二个年头的时候继续高速地发展,不过尽管我们十分犹豫,我们还是决定在 Swift 2.0 测试版发布以前就开始写作。几乎没有别的语言能够在如此短的时间里就能吸引这么多的开发者前来使用。
但是这留给了我们一个问题,你如何写出“符合语言习惯”的 Swift 代码?对某一个任务,有正确的做法吗?标准库给了我们一些提示,但是我们知道,即使是标准库本身也会随时间发生变化,它常常抛弃一切约定,又去遵守另一些约定。不过,在过去三年里,Swift 高速进化着,而优秀的 Swift 代码标准也日益明确。
对于从其他语言迁移过来的开发者,Swift 可能看起来很像你原来使用的语言,特别是它可能拥有你原来的语言中你最喜欢的那一部分。它可以像 C 一样进行低层级的位操作,但又可以避免许多未定义行为的陷阱。Ruby 的教徒可以在像是 map 或 filter 的轻量级的尾随闭包中感受到宾至如归。Swift 的泛型和 C++ 的模板如出一辙,但是额外的类型约束能保证泛型方法在被定义时就是正确的,而不必等到使用的时候再进行判定。灵活的高阶函数和运算符重载让你能够以 Haskell 或者 F# 那样的风格进行编码。最后 @objc 和 dynamic 关键字允许你像在 Objective-C 中那样使用 selector 和各种运行时的动态特性。
有了这些相似点,Swift 可以去适应其他语言的风格。比如,Objective-C 的项目可以自动地导入到 Swift 中,很多 Java 或者 C# 的设计模式也可以直接照搬过来使用。在 Swift 发布的前几个月,一大波关于单子 (monad) 的教程和博客也纷至杳来。
但是失望也接踵而至。为什么我们不能像 Java 中接口那样将协议扩展 (protocol extension) 和关联类型 (associated type) 结合起来使用?为什么数组不具有我们预想那样的协变 (covariant) 特性?为什么我们无法写出一个“函子” (functor)?有时候这些问题的答案是 Swift 还没有来得及实现这部分功能,但是更多时候,这是因为在 Swift 中有其他更适合这门语言的方式来完成这些任务,或者是因为 Swift 中这些你认为等价的特性其实和你原来的想象大有不同。
译者注:数组的协变特性指的是,包含有子类型对象的数组,可以直接赋值给包含有父类型对象的数组的变量。比如在 Java 和 C# 中
string是object的子类型,而对应的数组类型string[]可以直接赋值给声明为object[]类型的变量。但是在 Swift 中,Array<Parent>和Array<Child>之间并没有这样的关系。
和其他大多数编程语言一样,Swift 也是一门复杂的语言。但是它将这些复杂的细节隐藏得很好。你可以使用 Swift 迅速上手开发应用,而不必知晓泛型,重载或者是静态调用和动态派发之间的区别这些知识。你可能永远都不会需要去调用 C 语言的代码,或者实现自定义的集合类型。但是随着时间的推移,无论是想要提升你的代码的性能,还是想让程序更加优雅清晰,亦或只是为了完成某项开发任务,你都有可能要逐渐接触到这些事情。
带你深入地学习这些特性就是这本书的写作目的。我们在书中尝试回答了很多“这个要怎么做”以及“为什么在 Swift 中会是这个结果”这样的问题,这种问题遍布各个论坛。我们希望你一旦阅读过本书,就能把握这些语言基础的知识,并且了解很多 Swift 的进阶特性,从而对 Swift 是如何工作的有一个更好的理解。本书中的知识点可以说是一个高级 Swift 程序员所必须了解和熟悉的内容。
本书所面向的读者
本书面向的是有经验的程序员,你不需要是程序开发的专家,不过你应该已经是 Apple 平台的开发者,或者是想要从其他比如 Java 或者 C++ 这样的语言转行过来的程序员。如果你想要把你的 Swift 相关知识技能提升到和你原来已经熟知的 Objective-C 或者其他语言的同一水平线上的话,这本书会非常适合你。本书也适合那些已经开始学习 Swift,对这门语言基础有一定了解,并且渴望再上一个层次的新程序员们。
这本书不是一本介绍 Swift 基础的书籍,我们假定你已经熟悉这门语言的语法和结构。如果你需要完整地学习 Swift 的基础知识,最好的资源是 Apple 的 Swift 相关书籍 (在 iBooks 以及 Apple 开发者网站上均有下载)。如果你很有把握,你可以尝试同时阅读我们的这本书和 Apple 的 Swift 书籍。
这也不是一本教你如何为 macOS 或者 iOS 编程的书籍。不可否认,Swift 现在主要用于 Apple 的平台,我们会尽量包含一些实践中使用的例子,但是我们更希望这本书可以对非 Apple 平台的程序员也有所帮助。本书中绝大部分的例子应该可以无缝运行在其他操作系统中。那些不能运行的代码,要么是由于它们是彻底与 Apple 平台绑定的 (比如它们使用了 iOS 的框架或者依赖于 Objective-C 运行时),要么可以通过很小的更改就行运行,比如我们在生成随机数时就使用了 Linux 下的对应函数来替换 Apple 平台的 BSD 中的函数。
主题
我们按照基本概念的主题来组织本书,其中有一些深入像是可选值和字符串这样基本概念的章节,也有对于像是 C 语言互用性方面的主题。不过纵观全书,有一些主题可以为描绘出 Swift 给人的总体印象:
Swift 既是一门高层级语言,又是一门低层级语言。你可以在 Swift 中用 map 或者 reduce 来写出十分类似于 Ruby 和 Python 的代码,你也可以很容易地创建自己的高阶函数。Swift 让你有能力快速完成代码编写,并将它们直接编译为原生的二进制可执行文件,这使得性能上可以与 C 代码编写的程序相媲美。
Swift 真正激动人心,以及令人赞叹的是,我们可以兼顾高低两个层级。将一个数组通过闭包表达式映射到另一个数组所编译得到的汇编码,与直接对一块连续内存进行循环所得到的结果是一致的。
不过,为了最大化利用这些特性,有一些知识是你需要掌握的。如果你能对结构体和类的区别有深刻理解,或者对动态和静态方法派发的不同了然于胸的话,你就能从中获益。我们将在之后更深入地介绍这些内容。
Swift 是一门多范式的语言。你可以用 Swift 来编写面向对象的代码,也可以使用不变量的值来写纯函数式的程序,在必要的时候,你甚至还能使用指针运算来写和 C 类似的代码。
这是一把双刃剑。好的一面,在 Swift 中你将有很多可用工具,你也不会被限制在一种代码写法里。但是这也让你身临险境,因为可能你实际上会变成使用 Swift 语言来书写 Java 或者 C 或者 Objective-C 的代码。
Swift 仍然可以使用大部分 Objective-C 的功能,包括消息发送,运行时的类型判定,以及键值观察 (KVO) 等。但是 Swift 还引入了很多 Objective-C 中不具备的特性。
Erik Meijer 是一位著名的程序语言专家,他在 2015 年 10 月发推说道:
现在,相比 Haskell,Swift 可能是更好,更有价值,也更合适用来的学习函数式编程的语言。
Swift 拥有泛型,协议,值类型以及闭包等特性,这些特性是对函数式风格的很好的介绍。我们甚至可以将运算符和函数结合起来使用。在 Swift 早期的时候,这门语言为世界带来了很多关于单子 (monad) 的博客。不过等到 Swift 2.0 发布并引入协议扩展的时候,大家研究的趋势也随之变化。
Swift 十分灵活。在 On Lisp 这本书的介绍中,Paul Graham 写到:
富有经验的 Lisp 程序员将他们的程序拆分成不同的部分。除了自上而下的设计原则,他们还遵循一种可以被称为自下而上的设计,他们可以将语言进行改造,让它更适合解决当前的问题。在 Lisp 中,你并不只是使用这门语言来编写程序,在开发过程中,你同时也在构建这门语言。当你编写代码的时候,你可能会想“要是 Lisp 有这个或者这个运算符就好了”,之后你就真的可以去实现一个这样的运算符。事后来看,你会意识到使用新的运算符可以简化程序的某些部分的设计,语言和程序就这样相互影响,发展进化。
Swift 的出现比 Lisp 要晚得多,不过,我们能强烈感受到 Swift 也鼓励从下向上的编程方式。这让我们能轻而易举地编写一些通用可重用组件,然后你可以将它们组合起来实现更强大的的特性,最后用它们来解决你的实际问题。Swift 非常适合用来构建这些组件,你可以使它们看起来就像是语言自身的一部分。一个很好的例子就是 Swift 的标准库,许多你能想到的基本组件 - 像是可选值和基本的运算符等 - 其实都不是直接在语言本身中定义的,相反,它们是在标准库中被实现的。
Swift 代码可以做到紧凑,精确,同时保持清晰。Swift 使用相对简洁的代码,这并不意味着单纯地减少输入量,还标志了一个更深层次的目标。Swift 的观点是通过抛弃你经常在其他语言中见到的模板代码,而使得代码更容易被理解和阅读。这些模板代码往往会成为理解程序的障碍,而非助力。
举个例子,有了类型推断,在上下文很明显的时候我们就不再需要乱七八糟的类型声明了;那些几乎没有意义的分号和括号也都被移除了;泛型和协议扩展让你免于重复,并且把通用的操作封装到可以复用的方法中去。这些特性最终的目的都是为了能够让代码看上去一目了然。
一开始,这可能会对你造成一些困扰。如果你以前从来没有用像是 map,filter 和 reduce 这样的函数的话,它们可能看起来比简单的 for 循环要难理解。但是我们相信这个学习过程会很短,并且作为回报,你会发现这样的代码你第一眼看上去就能更准确地判断出它“显然正确”。
除非你有意为之,否则 Swift 在实践中总是安全的。Swift 和 C 或者 C++ 这样的语言不同,在那些语言中,你只要忘了做某件事情,你的代码很可能就不是安全的了。它和 Haskell 或者 Java 也不一样,在后两者中有时候不论你是否需要,它们都“过于”安全。
C# 的主要设计者之一的 Eric Lippert 在他关于创造 C# 的 10 件后悔的事情中总结了一些经验教训:
有时候你需要为那些构建架构的专家实现一些特性,这些特性应当被清晰地标记为危险 — 它们往往并不能很好地对应其他语言中某些有用的特性。
说这段话时,Eric 特别所指的是 C# 中的终止方法 (finalizer),它和 C++ 中的析构函数 (destructor) 比较类似。但是不同于析构函数,终止方法的运行是不确定的,它受命于垃圾回收器,并且运行在垃圾回收的线程上。更糟糕的是,很可能终止方法甚至完全不会被调用到。但是,在 Swift 中,因为采用的是引用计数,deinit 方法的调用是可以确定和预测的。
Swift 的这个特点在其他方面也有体现。未定义的和不安全的行为默认是被避免的。比如,一个变量在被初始化之前是不能使用的,使用越界下标访问数组将会抛出异常,而不是继续使用一个可能取到的错误值。
当你真正需要的时候,也有不少“不安全”的方式,比如 unsafeBitcast 函数,或者是 UnsafeMutablePointer 类型。但是强大能力的背后是更大的未定义行为的风险。 比如下面的代码:
var someArray = [1,2,3]
let uhOh = someArray.withUnsafeBufferPointer { ptr in
// ptr 只在这个 block 中有效
// 不过你完全可以将它返回给外部世界:
return ptr
}
// 稍后...
print(uhOh[10])
这段代码可以编译,但是天知道它最后会做什么。方法名里已经警告了你这是不安全的,所以对此你需要自己负责。
Swift 是一门独断的语言。关于“正确的” Swift 编码方法,作为本书作者,我们有着坚定的自己的看法。你会在本书中看到很多这方面的内容,有时候我们会把这些看法作为事实来对待。但是,归根结底,这只是我们的看法,你完全可以反对我们的观点。Swift 还是一门年轻的语言,许多事情还未成定局。更糟糕的是,很多博客或者文章是不正确的,或者已经过时 (包括我们曾经写过的一些内容,特别是早期就完成了的内容)。不论你在读什么资料,最重要的事情是你应当亲自尝试,去检验它们的行为,并且去体会这些用法。带着批判的眼光去审视和思考,并且警惕那些已经过时的信息。
Swift 在持续进化中。每年语法发生重大变化的时期可能已经离我们远去了,但是语言中的一些重要的部分依然大有可为,有的部分十分新颖 (比如字符串处理),有的部分还在剧烈变化 (比如泛型系统),而有的部分还尚待开发 (比如并行编程)。
术语
你用,或是不用,术语就在那里,不多不少。你懂,或是不懂,定义就在那里,不偏不倚。
程序员总是喜欢说行话。为了避免困扰,接下来我们会介绍一些贯穿于本书的术语定义。我们将尽可能遵守官方文档中的术语用法,使用被 Swift 社区所广泛接受的定义。这些定义大多都会在接下来的章节中被详细介绍,所以就算一开始你对它们一头雾水,也大可不必在意。即使你已经对这些术语非常了解,我们也还是建议你再浏览一下它们,并且确定你能接受我们的表述。
在 Swift 中,我们需要对值,变量,引用以及常量加以区分。
值 (value) 是不变的,永久的,它从不会改变。比如,1, true 和 [1,2,3] 都是值。这些是字面量 (literal) 的例子,值也可以是运行时生成的。当你计算 5 的平方时,你得到的数字也是一个值。
当我们使用 var x = [1,2] 来将一个值进行命名的时候,我们实际上创建了一个名为 x 的变量 (variable) 来持有 [1,2] 这个值。通过像是执行 x.append(3) 这样的操作来改变 x 时,我们并没有改变原来的值。相反,我们所做的是使用 [1,2,3] 这个新的值来替代原来 x 中的内容。可能实际上它的内部实现真的只是在某段内存的后面添加上一个条目,并不是全体的替换,但是至少从逻辑上来说值是全新的。我们将这个过程称为变量的改变 (mutating)。
我们还可以使用 let 而不是 var 来声明一个常量变量 (constant variables),或者简称为常量。一旦常量被赋予一个值,它就不能再次被赋一个新的值了。
我们不需要在一个变量被声明的时候就立即为它赋值。我们可以先对变量进行声明 (let x: Int),然后稍后再给它赋值 (x = 1)。Swift 是强调安全的语言,它将检查所有可能的代码路径,并确保变量在被读取之前一定是完成了赋值的。在 Swift 中变量不会存在未定义状态。当然,如果一个变量是用 let 声明的,那么它只能被赋值一次。
结构体 (struct) 和枚举 (enum) 是值类型 (value type)。当你把一个结构体变量赋值给另一个,那么这两个变量将会包含同样的值。你可以将它理解为内容被复制了一遍,但是更精确地描述的话,是被赋值的变量与另外的那个变量包含了同样的值。
引用 (reference) 是一种特殊类型的值:它是一个“指向”另一个值的值。两个引用可能会指向同一个值,这引入了一种可能性,那就是这个值可能会被程序的两个不同的部分所改变。
类 (class) 是引用类型 (reference type)。你不能在一个变量里直接持有一个类的实例 (我们偶尔可能会把这个实例称作对象 (object),这个术语经常被滥用,会让人困惑)。对于一个类的实例,我们只能在变量里持有对它的引用,然后使用这个引用来访问它。
引用类型具有同一性 (identity),也就是说,你可以使用 === 来检查两个变量是否确实引用了同一个对象。如果相应类型的 == 运算符被实现了的话,你也可以用 == 来判断两个变量是否相等。两个不同的对象按照定义也是可能相等的。
值类型不存在同一性的问题。比如你不能对某个变量判定它是否和另一个变量持有“相同”的数字 2。你只能检查它们都包含了 2 这个值。=== 运算符实际做的是询问“这两个变量是不是持有同样的引用”。在程序语言的论文里,== 有时候被称为结构相等,而 === 则被称为指针相等或者引用相等。
Swift 中,类引用不是唯一的引用类型。Swift 中依然有指针,比如使用 withUnsafeMutablePointer 和类似方法所得到的就是指针。不过类是使用起来最简单引用类型,这与它们的引用特性被部分隐藏在语法糖之后是不无关系的。你不需要像在其他一些语言中那样显式地处理指针的“解引用”。(我们会在稍后的互用性章节中详细提及其他种类的引用。)
一个引用变量也可以用 let 来声明,这样做会使引用变为常量。换句话说,这会使变量不能被改变为引用其他东西,不过很重要的是,这并不意味着这个变量所引用的对象本身不能被改变。所以,当用常量的方式来引用变量的时候要格外小心,只有指向关系被常量化了,而对象本身还是可变的。(如果前面这几句话看起来有些不明不白的话,不要担心,我们在结构体和类还会详细解释)。这一点造成的问题是,就算在一个声明变量的地方看到 let,你也不能一下子就知道声明的东西是不是完全不可变的。想要做出正确的判断,你必须先知道这个变量持有的是值类型还是引用类型。
我们通过值类型是否执行深复制来对它们分类,判断它们是否具有值语义 (value semantics)。这种复制可能是在赋值新变量时就发生的,也可能会延迟到变量内容发生变更的时候再发生。
这里我们会遇到另一件复杂的事情。如果我们的结构体中包含有引用类型,在将结构体赋值给一个新变量时所发生的复制行为中,这些引用类型的内容是不会被自动复制一份的,只有引用本身会被复制。这种复制的行为被称作浅复制 (shallow copy)。
举个例子,Foundation 框架中的 Data 结构体实际上是对引用类型 NSData 的一个封装。不过,Data 的作者采取了额外的步骤,来保证当 Data 结构体发生变化的时候对其中的 NSData 对象进行深复制。他们使用一种名为“写时复制” (copy-on-write) 的技术来保证操作的高效,我们会在结构体和类里详细介绍这种机制。现在我们需要重点知道的是,这种写时复制的特性并不是直接具有的,它需要额外进行实现。
Swift 中,像是数组这样的集合类型也都是对引用类型的封装,它们同样使用了写时复制的方式来在提供值语义的同时保持高效。不过,如果集合类型的元素是引用类型 (比如一个含有对象的数组) 的话,对象本身将不会被复制,只有对它的引用会被复制。也就是说,Swift 的数组只有当其中的元素满足值语义时,数组本身才具有值语义。
有些类是完全不可变的,也就是说,从被创建以后,它们就不提供任何方法来改变它们的内部状态。这意味着即使它们是类,它们依然具有值语义 (因为它们就算被到处使用也从不会改变)。 但是要注意的是,只有那些标记为 final 的类能够保证不被子类化,也不会被添加可变状态。
在 Swift 中,函数也是值。你可以将一个函数赋值给一个变量,也可以创建一个包含函数的数组,或者调用变量所持有的函数。如果一个函数接受别的函数作为参数 (比如 map 函数接受一个转换函数,并将其应用到数组中的所有元素上),或者一个函数的返回值是函数,那么这样的函数就叫做高阶函数 (higher-order function)。
函数不需要被声明在最高层级 — 你可以在一个函数内部声明另一个函数,也可以在一个 do 作用域或者其他作用域中声明函数。如果一个函数被定义在外层作用域中,但是被传递出这个作用域 (比如把这个函数被作为其他函数的返回值返回时),它将能够“捕获”局部变量。这些局部变量将存在于函数中,不会随着局部作用域的结束而消亡,函数也将持有它们的状态。这种行为的变量被称为“闭合变量”,我们把这样的函数叫做闭包 (closure)。
函数可以通过 func 关键字来定义,也可以通过 { } 这样的简短的闭包表达式 (closure expression) 来定义。有时候我们只把通过闭包表达式创建的函数叫做“闭包”,不过不要让这种叫法蒙蔽了你的双眼。实际上使用 func 关键字定义的函数,如果它包含了外部的变量,那么它也是一个闭包。
函数是引用类型。也就是说,将一个捕获了状态的函数赋值给另一个变量,并不会导致这些状态被复制。和对象引用类似,这些状态会被共享。换句话说,当两个闭包持有同样的局部变量时,它们是共享这个变量以及它的状态的。这可能会让你有点儿惊讶,我们将在函数一章中涉及这方面的更多内容。
定义在类或者协议中的函数就是方法 (method),它们有一个隐式的 self 参数。如果一个函数不是接受多个参数,而是只接受部分参数,然后返回一个接受其余参数的函数的话,那么这个函数就是一个柯里化函数 (curried function)。我们将在函数中讲解一个方法是如何成为柯里化函数的。有时候我们会把那些不是方法的函数叫做自由函数 (free function),这可以将它们与方法区分开来。
在 Swift 中,一个完整的函数名字不仅仅只包括函数的基本名 (括号前面的部分),也包括它的参数标签 (argument label)。举例来说,将一个集合中的索引移动给定步数的函数的全名是 index(_:offsetBy:),该函数接受两个参数 (由两个冒号表示),其中第一个参数没有标签 (用下划线表示)。在本书中,如果我们所提及的函数处于清晰的上下文中的话,我们通常会把标签省略掉 (编译器也允许你这么做)。
自由函数和那些在结构体上调用的方法是静态派发 (statically dispatched) 的。对于这些函数的调用,在编译的时候就已经确定了。对于静态派发的调用,编译器可能能够内联 (inline) 这些函数,也就是说,完全不去做函数调用,而是将函数调用替换为函数中需要执行的代码。优化器还还能够帮助丢弃或者简化那些在编译时就能确定不会被实际执行的代码。
类或者协议上的方法可能是动态派发 (dynamically dispatched) 的。编译器在编译时不需要知道哪个函数将被调用。在 Swift 中,这种动态特性要么由 vtable 来完成,要么通过 selector 和 objc_msgSend 来完成,前者的处理方式和 Java 或是 C++ 中类似,而后者只针对 @objc 的类和协议上的方法。
子类型和方法重写 (overriding)是实现多态 (polymorphic) 特性的手段,也就是说,根据类型的不同,同样的方法会呈现出不同的行为。另一种方式是函数重载 (overloading),它是指为不同的类型多次写同一个函数的行为。(注意不要把重写和重载弄混了,它们是完全不同的。)实现多态的第三种方法是通过泛型,也就是一次性地编写能够接受任意类型的的函数或者方法,不过这些方法的实现会各有不同。与方法重写不同的是,泛型中的方法在编译期间就是静态已知的。我们会在泛型章节中提及关于这方面的更多内容。
Swift 风格指南
当我们编写这本书,或者在我们自己的项目中使用 Swift 代码时,我们尽量遵循如下的原则:
对于命名,在使用时能清晰表意是最重要。因为 API 被使用的次数要远远多于被声明的次数,所以我们应当从使用者的角度来考虑它们的名字。尽快熟悉 Swift API 设计准则,并且在你自己的代码中坚持使用这些准则。
简洁经常有助于代码清晰,但是简洁本身不应该独自成为我们编码的目标。
务必为函数添加文档注释 — 特别是泛型函数。
类型使用大写字母开头,函数、变量和枚举成员使用小写字母开头,两者都使用驼峰式命名法。
使用类型推断。省略掉显而易见的类型会有助于提高可读性。
如果存在歧义或者在进行定义的时候不要使用类型推断。(比如
func就需要显式地指定返回类型)优先选择结构体,只在确实需要使用到类特有的特性或者是引用语义时才使用类。
除非你的设计就是希望某个类被继承使用,否则都应该将它们标记为
final。除非一个闭包后面立即跟随有左括号,否则都应该使用尾随闭包 (trailing closure) 的语法。
使用
guard来提早退出方法。避免对可选值进行强制解包和隐式强制解包。它们偶尔有用,但是经常需要使用它们的话往往意味着有其他不妥的地方。
不要写重复的代码。如果你发现你写了好几次类似的代码片段的话,试着将它们提取到一个函数里,并且考虑将这个函数转化为协议扩展的可能性。
试着去使用
map和reduce,但这不是强制的。当合适的时候,使用for循环也无可厚非。高阶函数的意义是让代码可读性更高。但是如果使用reduce的场景难以理解的话,强行使用往往事与愿违,这种时候简单的for循环可能会更清晰。试着去使用不可变值:除非你需要改变某个值,否则都应该使用
let来声明变量。不过如果能让代码更加清晰高效的话,也可以选择使用可变的版本。用函数将可变的部分封装起来,可以把它带来的副作用进行隔离。Swift 的泛型可能会导致非常长的函数签名。坏消息是我们现在除了将函数声明强制写成几行以外,对此并没有什么好办法。我们会在示例代码中在这点上保持一贯性,这样你能看到我们是如何处理这个问题的。
除非你确实需要,否则不要使用
self.。不过在闭包表达式中,self是被强制使用的,这是一个清晰的信号,表明闭包将会捕获self。尽可能地对现有的类型和协议进行扩展,而不是写一些全局函数。这有助于提高可读性,让别人更容易发现你的代码。
最后,关于整本书中的示例代码我们还有一点补充说明:为了节省空间并且专注于重要的部分,我们通常会省略 import 语句,这往往会导致代码无法编译。如果你想要自己尝试运行这些示例代码,而编译器告诉你它不认识某个特定的符号的话,请尝试添加 import Foundation 或者 import UIKit 这样的语句。
内建集合类型
在所有的编程语言中,元素的集合都是最重要的数据类型。在语言层面上对于不同类型的容器的良好支持,是决定编程效率和幸福指数的重要因素。Swift 在序列和集合这方面进行了特别的强调,标准库的开发者对于该话题的内容所投入的精力远超其他部分。正是有了这样的努力,我们能够使用到非常强大的集合模型,它比你所习惯的其他语言的集合拥有更好的可扩展性,不过同时它也相当复杂。
在本章中,我们将会讨论 Swift 中内建的几种主要集合类型,并重点研究如何以符合语言习惯的方式高效地使用它们。在下一章中,我们会沿着抽象的阶梯蜿蜒而上,去探究标准库中的集合协议的工作原理。
数组
数组和可变性
在 Swift 中最常用的集合类型非数组莫属。数组是一个容器,它以有序的方式存储一系列相同类型的元素,对于其中每个元素,我们可以使用下标对其直接进行访问 (这又被称作随机访问)。举个例子,要创建一个数字的数组,我们可以这么写:
// 斐波那契数列
let fibs = [0, 1, 1, 2, 3, 5]
要是我们使用像是 append(_:) 这样的方法来修改上面定义的数组的话,会得到一个编译错误。这是因为在上面的代码中数组是用 let 声明为常量的。在很多情景下,这是正确的做法,它可以避免我们不小心对数组做出改变。如果我们想按照变量的方式来使用数组,我们需要将它用 var 来进行定义:
var mutableFibs = [0, 1, 1, 2, 3, 5]
现在我们就能很容易地为数组添加单个或是一系列元素了:
mutableFibs.append(8)
mutableFibs.append(contentsOf: [13, 21])
mutableFibs // [0, 1, 1, 2, 3, 5, 8, 13, 21]
区别使用 var 和 let 可以给我们带来不少好处。使用 let 定义的变量因为其具有不变性,因此更有理由被优先使用。当你读到类似 let fibs = ... 这样的声明时,你可以确定 fibs 的值将永远不变,这一点是由编译器强制保证的。这在你需要通读代码的时候会很有帮助。不过,要注意这只针对那些具有值语义的类型。使用 let 定义的类实例对象 (也就是说对于引用类型) 时,它保证的是这个引用永远不会发生变化,你不能再给这个引用赋一个新的值,但是这个引用所指向的对象却是可以改变的。我们将在结构体和类中更加详尽地介绍两者的区别。
数组和标准库中的所有集合类型一样,是具有值语义的。当你创建一个新的数组变量并且把一个已经存在的数组赋值给它的时候,这个数组的内容会被复制。举个例子,在下面的代码中,x 将不会被更改:
var x = [1,2,3]
var y = x
y.append(4)
y // [1, 2, 3, 4]
x // [1, 2, 3]
var y = x 语句复制了 x,所以在将 4 添加到 y 末尾的时候,x 并不会发生改变,它的值依然是 [1,2,3]。当你把一个数组传递给一个函数时,会发生同样的事情;方法将得到这个数组的一份本地复制,所有对它的改变都不会影响调用者所持有的数组。
对比一下 Foundation 框架中 NSArray 在可变特性上的处理方法。NSArray 中没有更改方法,想要更改一个数组,你必须使用 NSMutableArray。但是,就算你拥有的是一个不可变的 NSArry,但是它的引用特性并不能保证这个数组不会被改变:
let a = NSMutableArray(array: [1,2,3])
// 我们不想让 b 发生改变
let b: NSArray = a
// 但是事实上它依然能够被 a 影响并改变
a.insert(4, at: 3)
b // ( 1, 2, 3, 4 )
正确的方式是在赋值时,先手动进行复制:
let c = NSMutableArray(array: [1,2,3])
// 我们不想让 d 发生改变
let d = c.copy() as! NSArray
c.insert(4, at: 3)
d // ( 1, 2, 3 )
在上面的例子中,显而易见,我们需要进行复制,因为 a 的声明毕竟就是可变的。但是,当把数组在方法和函数之间来回传递的时候,事情可能就不那么明显了。
在 Swift 中,数组只有一种统一的类型,可以通过在声明时使用 var 而非 let 来将数组定义为可变的。当你使用 let 声明第二个数组,并将第一个数组赋值给它时,可以保证这个新的数组是不会改变的,因为这里没有共用的引用。
创建如此多的复制有可能造成性能问题,不过实际上 Swift 标准库中的所有集合类型都使用了“写时复制”这一技术,它能够保证只在必要的时候对数据进行复制。在我们的例子中,直到 y.append 被调用的之前,x 和 y 都将共享内部的存储。在结构体和类中我们也将仔细研究值语义,并告诉你如何为你自己的类型实现写时复制特性。
数组和可选值
Swift 数组提供了你能想到的所有常规操作方法,像是 isEmpty 或是 count。数组也允许直接使用特定的下标直接访问其中的元素,像是 fibs[3]。不过要牢记在使用下标获取元素之前,你需要确保索引值没有超出范围。比如获取索引值为 3 的元素,你需要保证数组中至少有 4 个元素。否则,你的程序将会崩溃。
这么设计主要是由数组索引的使用方式决定的。在 Swift 中,实际上计算一个索引值这种操作是非常罕见的:
想要迭代数组?
for x in array想要迭代除了第一个元素以外的数组其余部分?
for x in array.dropFirst()想要迭代除了最后 5 个元素以外的数组?
for x in array.dropLast(5)想要列举数组中的元素和对应的下标?
for (num, element) in collection.enumerated()想要寻找一个指定元素的位置?
if let idx = array.index { someMatchingLogic($0) }想要对数组中的所有元素进行变形?
array.map { someTransformation($0) }想要筛选出符合某个标准的元素?
array.filter { someCriteria($0) > }
译者注:虽然原文表示现在的数组索引值的设计原因是索引很少需要计算,但是个人认为这种说法有失偏颇。标准库中的数组下标索引之所以需要程序员保证索引有效,大概有两方面的考虑。首先是性能上的优化,在 Swift 数组下标方法内部,存在对下标越界的安全特性的检查。当我们将优化器的优化级别设置为
-Ounchecked时,这些检查将不会执行,这可以给我们带来更高的访问性能。但如果标准库中设计的是“可失败”的下标访问的话,这项优化将无法进行。另外,下标越界这样的错误应该归结于程序员的错误,通过运行时来“遮蔽”这种错误,往往会带来更大的问题。至于上面那些让使用者可以不进行索引计算的简便方法,更多的是结果而非原因。
Swift 3 中传统的 C 风格的 for 循环被移除了,这是 Swift 不鼓励你去做索引计算的另一个标志。手动计算和使用索引值往往可能带来很多潜在的 bug,所以最好避免这么做。如果这不可避免的话,我们可以很容易写一个可重用的通用函数来进行处理,在其中你可以对精心测试后的索引计算进行封装,我们将在泛型一章里看到这个例子。
但是有些时候你仍然不得不使用索引。对于数组索引来说,当你这么做时,你应该已经深思熟虑,对背后的索引计算逻辑进行过认真思考。在这个前提下,如果每次都要对获取的结果进行解包的话就显得多余了。因为这意味着你不信任你的代码。但实际上你是信任你自己的代码的,所以你可能会选择将结果进行强制解包,因为你知道这些下标都是有效的。这一方面十分麻烦,另一方面也是一个坏习惯。当强制解包变成一种习惯后,很可能你会不小心强制解包了本来不应该解包的东西。所以,为了避免这个行为变成习惯,数组根本没有给你可选值的选项。
无效的下标操作会造成可控的崩溃,有时候这种行为可能会被叫做不安全,但是这只是安全性的一个方面。下标操作在内存安全的意义上是完全安全的,标准库中的集合总是会执行边界检查,并禁止那些越界索引对内存的访问。
其他操作的行为略有不同。first 和 last 属性本身是可选值类型,当数组为空时,它们返回 nil。first 相当于 isEmpty ? nil : self[0]。类似地,如果数组为空时,removeLast 将会导致崩溃,而 popLast 将在数组不为空时删除最后一个元素并返回它,在数组为空时,它将不执行任何操作,直接返回 nil。你应该根据自己的需要来选取到底使用哪一个:当你将数组当作栈来使用时,你可能总是想要将 empty 检查和移除最后元素组合起来使用;而另一方面,如果你已经知道数组一定非空,那再去处理可选值就完全没有必要了。
我们会在本章后面讨论字典的时候再次遇到关于这部分的权衡。除此之外,关于可选值我们会有一整章的内容对它进行讨论。
数组变形
Map
对数组中的每个值执行转换操作是一个很常见的任务。每个程序员可能都写过上百次这样的代码:创建一个新数组,对已有数组中的元素进行循环依次取出其中元素,对取出的元素进行操作,并把操作的结果加入到新数组的末尾。比如,下面的代码计算了一个整数数组里的元素的平方:
var squared: [Int] = []
for fib in fibs {
squared.append(fib * fib)
}
squared // [0, 1, 1, 4, 9, 25]
Swift 数组拥有 map 方法,这个方法来自函数式编程的世界。下面的例子使用了 map 来完成同样的操作:
let squares = fibs.map { fib in fib * fib }
squares // [0, 1, 1, 4, 9, 25]
这种版本有三大优势。首先,它很短。长度短一般意味着错误少,不过更重要的是,它比原来更清晰。所有无关的内容都被移除了,一旦你习惯了 map 满天飞的世界,你就会发现 map 就像是一个信号,一旦你看到它,就会知道即将有一个函数被作用在数组的每个元素上,并返回另一个数组,它将包含所有被转换后的结果。
其次,squared 将由 map 的结果得到,我们不会再改变它的值,所以也就不再需要用 var 来进行声明了,我们可以将其声明为 let。另外,由于数组元素的类型可以从传递给 map 的函数中推断出来,我们也不再需要为 squared 显式地指明类型了。
最后,创造 map 函数并不难,你只需要把 for 循环中的代码模板部分用一个泛型函数封装起来就可以了。下面是一种可能的实现方式 (在 Swift 中,它实际上是 Sequence 的一个扩展,我们将在之后关于编写泛型算法的章节里继续 Sequence 的话题):
extension Array {
func map<T>(_ transform: (Element) -> T) -> [T] {
var result: [T] = []
result.reserveCapacity(count)
for x in self {
result.append(transform(x))
}
return result
}
}
Element 是数组中包含的元素类型的占位符,T 是元素转换之后的类型的占位符。map 函数本身并不关心 Element 和 T 究竟是什么,它们可以是任意类型。T 的具体类型将由调用者传入给 map 的 transform 方法的返回值类型来决定。
实际上,这个函数的签名应该是
func map<T>(_ transform: (Element) throws -> T) rethrows -> [T]也就是说,对于可能抛出错误的变形函数,
map将会把错误转发给调用者。我们会在错误处理一章里覆盖这个细节。在这里,我们选择去掉错误处理的这个修饰,这样看起来会更简单一些。如果你感兴趣,可以看看 GitHub 上 Swift 仓库的Sequence.map的源码实现。
使用函数将行为参数化
即使你已经很熟悉 map 了,也请花一点时间来想一想 map 的代码。是什么让它可以如此通用而且有用?
map 可以将模板代码分离出来,这些模板代码并不会随着每次调用发生变动,发生变动的是那些功能代码,也就是如何变换每个元素的逻辑代码。map 函数通过接受调用者所提供的变换函数作为参数来做到这一点。
纵观标准库,我们可以发现很多这样将行为进行参数化的设计模式。标准库中有不下十多个函数接受调用者传入另一个函数,并将它作为函数执行的关键步骤:
map和flatMap— 如何对元素进行变换filter— 元素是否应该被包含在结果中reduce— 如何将元素合并到一个总和的值中sequence— 序列中下一个元素应该是什么?forEach— 对于一个元素,应该执行怎样的操作sort,lexicographicCompare和partition— 两个元素应该以怎样的顺序进行排列index,first和contains— 元素是否符合某个条件min和max— 两个元素中的最小/最大值是哪个elementsEqual和starts— 两个元素是否相等split— 这个元素是否是一个分割符prefix- 当判断为真的时候,将元素滤出到结果中。一旦不为真,就将剩余的抛弃。和filter类似,但是会提前退出。这个函数在处理无限序列或者是延迟计算 (lazily-computed) 的序列时会非常有用。drop- 当判断为真的时候,丢弃元素。一旦不为真,返回将其余的元素。和prefix(while:)类似,不过返回相反的集合。
所有这些函数的目的都是为了摆脱代码中那些杂乱无用的部分,比如像是创建新数组,对源数据进行 for 循环之类的事情。这些杂乱代码都被一个单独的单词替代了。这可以重点突出那些程序员想要表达的真正重要的逻辑代码。
这些函数中有一些拥有默认行为。除非你进行过指定,否则 sort 默认将会把可以作比较的元素按照升序排列。contains 对于可以判等的元素,会直接检查两个元素是否相等。这些默认行为让代码变得更加易读。升序排列非常自然,因此 array.sort() 的意义也很符合直觉。而对于 array.index(of: "foo") 这样的表达方式,也要比 array.index { $0 == "foo" } 更容易理解。
不过在上面的例子中,它们都只是特殊情况下的简写。集合中的元素并不一定需要可以作比较,也不一定需要可以判等。你可以不对整个元素进行操作,比如,对一个包含 Person 对象的数组,你可以通过他们的年龄进行排序 (people.sort { $0.age < $1.age }),或者是检查集合中有没有包含未成年人 (people.contains { $0.age < 18 })。你也可以对转变后的元素进行比较,比如通过 people.sort { $0.name.uppercased() < $1.name.uppercased() } 来进行忽略大小写的排序,虽然这么做的效率不会很高。
还有一些其他类似的很有用的函数,可以接受一个函数来指定行为。虽然它们并不存在于标准库中,但是你可以很容易地自己定义和实现它们,我们也建议你自己尝试着做做看:
accumulate— 累加,和reduce类似,不过是将所有元素合并到一个数组中,并保留合并时每一步的值。all(matching:)和none(matching:)— 测试序列中是不是所有元素都满足某个标准,以及是不是没有任何元素满足某个标准。它们可以通过contains和它进行了精心对应的否定形式来构建。count(where:)— 计算满足条件的元素的个数,和filter相似,但是不会构建数组。indices(where:)— 返回一个包含满足某个标准的所有元素的索引的列表,和index(where:)类似,但是不会在遇到首个元素时就停止。
我们在本书的其他地方进行了定义和实现了其中的部分函数。
有时候你可能会发现你写了好多次同样模式的代码,比如想要在一个逆序数组中寻找第一个满足特定条件的元素:
let names = ["Paula", "Elena", "Zoe"]
var lastNameEndingInA: String?
for name in names.reversed() where name.hasSuffix("a") {
lastNameEndingInA = name
break
}
lastNameEndingInA // Optional("Elena")
在这种情况下,你可以考虑为 Sequence 添加一个小扩展,来将这个逻辑封装到 last(where:) 方法中。我们使用函数参数来对 for 循环中发生的变化进行抽象描述:
extension Sequence {
func last(where predicate: (Element) -> Bool) -> Element? {
for element in reversed() where predicate(element) {
return element
}
return nil
}
}
现在我们就能把代码中的 for 循环换成 findElement 了:
let match = names.last { $0.hasSuffix("a") }
match // Optional("Elena")
这么做的好处和我们在介绍 map 时所描述的是一样的,相较 for 循环,last(where:) 的版本显然更加易读。虽然 for 循环也很简单,但是在你的头脑里你始终还是要去做个循环,这加重了理解的负担。使用 last(where:) 可以减少出错的可能性,而且它允许你使用 let 而不是 var 来声明结果变量。
它和 guard 一起也能很好地工作,可能你会想要在元素没被找到的情况下提早结束代码:
guard let match = someSequence.last(where: { $0.passesTest() })
else { return }
// 对 match 进行操作
我们在本书后面会进一步涉及扩展集合类型和使用函数的相关内容。
可变和带有状态的闭包
当遍历一个数组的时候,你可以使用 map 来执行一些其他操作 (比如将元素插入到一个查找表中)。我们不推荐这么做,来看看下面这个例子:
array.map { item in
table.insert(item)
}
这将副作用 (改变了查找表) 隐藏在了一个看起来只是对数组变形的操作中。在上面这样的例子中,使用简单的 for 循环显然是比使用 map 这样的函数更好的选择。我们有一个叫做 forEach 的函数,看起来很符合我们的需求,但是 forEach 本身存在一些问题,我们一会儿会详细讨论。
这种做法和故意给闭包一个局部状态有本质不同。闭包是指那些可以捕获自身作用域之外的变量的函数,闭包再结合上高阶函数,将成为强大的工具。举个例子,方才我们提到的 accumulate 函数就可以用 map 结合一个带有状态的闭包来进行实现:
extension Array {
func accumulate<Result>(_ initialResult: Result,
_ nextPartialResult: (Result, Element) -> Result) -> [Result]
{
var running = initialResult
return map { next in
running = nextPartialResult(running, next)
return running
}
}
}
这个函数创建了一个中间变量来存储每一步的值,然后使用 map 来从这个中间值逐步计算结果数组:
[1,2,3,4].accumulate(0, +) // [1, 3, 6, 10]
要注意的是,这段代码假设了变形函数是以序列原有的顺序执行的。在我们上面的 map 中,事实确实如此。但是也有可能对于序列的变形是无序的,比如我们可以有并行处理元素变形的实现。官方标准库中的 map 版本没有指定它是否会按顺序来处理序列,不过看起来现在这么做是安全的。
Filter
另一个常见操作是检查一个数组,然后将这个数组中符合一定条件的元素过滤出来并用它们创建一个新的数组。对数组进行循环并且根据条件过滤其中元素的模式可以用数组的 filter 方法表示:
let nums = [1,2,3,4,5,6,7,8,9,10]
nums.filter { num in num % 2 == 0 } // [2, 4, 6, 8, 10]
我们可以使用 Swift 内建的用来代表参数的简写 $0,这样代码将会更加简短。我们可以不用写出 num 参数,而将上面的代码重写为:
nums.filter { $0 % 2 == 0 } // [2, 4, 6, 8, 10]
对于很短的闭包来说,这样做有助于提高可读性。但是如果闭包比较复杂的话,更好的做法应该是就像我们之前那样,显式地把参数名字写出来。不过这更多的是一种个人选择,使用一眼看上去更易读的版本就好。一个不错的原则是,如果闭包可以很好地写在一行里的话,那么使用简写名会更合适。
通过组合使用 map 和 filter,我们现在可以轻易完成很多数组操作,而不需要引入中间变量。这会使得最终的代码变得更短更易读。比如,寻找 100 以内同时满足是偶数并且是其他数字的平方的数,我们可以对 0..<10 进行 map 来得到所有平方数,然后再用 filter 过滤出其中的偶数:
(1..<10).map { $0 * $0 }.filter { $0 % 2 == 0 } // [4, 16, 36, 64]
filter 的实现看起来和 map 很类似:
extension Array {
func filter(_ isIncluded: (Element) -> Bool) -> [Element] {
var result: [Element] = []
for x in self where isIncluded(x) {
result.append(x)
}
return result
}
}
如果你对在 for 中所使用的 where 感兴趣的话,可以阅读可选值一章。
一个关于性能的小提示:如果你正在写下面这样的代码,请不要这么做!
bigArray.filter { someCondition }.count > 0
filter 会创建一个全新的数组,并且会对数组中的每个元素都进行操作。然而在上面这段代码中,这显然是不必要的。上面的代码仅仅检查了是否有至少一个元素满足条件,在这个情景下,使用 contains(where:) 更为合适:
bigArray.contains { someCondition }
这种做法会比原来快得多,主要因为两个方面:它不会去为了计数而创建一整个全新的数组,并且一旦找到了第一个匹配的元素,它就将提前退出。一般来说,你只应该在需要所有结果时才去选择使用 filter。
有时候你会发现你想用 contains 完成一些操作,但是写出来的代码看起来很糟糕。比如,要是你想检查一个序列中的所有元素是否全部都满足某个条件,你可以用 !sequence.contains { !condition },其实你可以用一个更具有描述性名字的新函数将它封装起来:
extension Sequence {
public func all(matching predicate: (Element) -> Bool) -> Bool {
// 对于一个条件,如果没有元素不满足它的话,那意味着所有元素都满足它:
return !contains { !predicate($0) }
}
}
let evenNums = nums.filter { $0 % 2 == 0 } // [2, 4, 6, 8, 10]
evenNums.all { $0 % 2 == 0 } // true
Reduce
map 和 filter 都作用在一个数组上,并产生另一个新的、经过修改的数组。不过有时候,你可能会想把所有元素合并为一个新的值。比如,要是我们想将元素的值全部加起来,可以这样写:
let fibs = [0, 1, 1, 2, 3, 5]
var total = 0
for num in fibs {
total = total + num
}
total // 12
reduce 方法对应这种模式,它把一个初始值 (在这里是 0) 以及一个将中间值 (total) 与序列中的元素 (num) 进行合并的函数进行了抽象。使用 reduce,我们可以将上面的例子重写为这样:
let sum = fibs.reduce(0) { total, num in total + num } // 12
运算符也是函数,所以我们也可以把上面的例子写成这样:
fibs.reduce(0, +) // 12
reduce 的输出值的类型可以和输入的类型不同。举个例子,我们可以将一个整数的列表转换为一个字符串,这个字符串中每个数字后面跟一个空格:
fibs.reduce("") { str, num in str + "\(num), " } // 0, 1, 1, 2, 3, 5,
reduce 的实现是这样的:
extension Array {
func reduce<Result>(_ initialResult: Result,
_ nextPartialResult: (Result, Element) -> Result) -> Result
{
var result = initialResult
for x in self {
result = nextPartialResult(result, x)
}
return result
}
}
另一个关于性能的小提示:reduce 相当灵活,所以在构建数组或者是执行其他操作时看到 reduce 的话不足为奇、比如,你可以只使用 reduce 就能实现 map 和 filter:
extension Array {
func map2<T>(_ transform: (Element) -> T) -> [T] {
return reduce([]) {
$0 + [transform($1)]
}
}
func filter2(_ isIncluded: (Element) -> Bool) -> [Element] {
return reduce([]) {
isIncluded($1) ? $0 + [$1] : $0
}
}
}
这样的实现符合美学,并且不再需要那些啰嗦的命令式的 for 循环。但是 Swift 不是 Haskell,Swift 的数组并不是列表 (list)。在这里,每次执行 combine 函数都会通过在前面的元素之后附加一个变换元素或者是已包含的元素,并创建一个全新的数组。这意味着上面两个实现的复杂度是 O(n2),而不是 O(n)。随着数组长度的增加,执行这些函数所消耗的时间将以平方关系增加。
reduce 还有另外一个版本,它的类型有所不同。具体来说,负责将中间结果和某个元素合并的函数,现在接受一个 inout 的 Result 作为参数:
public func reduce<Result>(into initialResult: Result,
_ updateAccumulatingResult:
(_ partialResult: inout Result, Element) throws -> ()
) rethrows -> Result
我们会在结构体和类的相关章节中探究 inout 参数的细节,现在的话,你可以把 inout Result 看作是一个可变的参数:我们可以在函数内部更改它。这让我们可以以一种高效得多的方式重写 filter:
extension Array {
func filter3(_ isIncluded: (Element) -> Bool) -> [Element] {
return reduce(into: []) { result, element in
if isIncluded(element) {
result.append(element)
}
}
}
}
当使用 inout 是,编译器不会每次都创建一个新的数组,这样一来,这个版本的 filter 时间复杂度再次回到了 O(n)。当 reduce(into:_:) 的调用被编译器内联时,生成的代码通常会和使用 for 循环所得到的代码是一致的。
flatMap
有时候我们会想要对一个数组用一个函数进行 map,但是这个变形函数返回的是另一个数组,而不是单独的元素。
举个例子,假如我们有一个叫做 extractLinks 的函数,它会读取一个 Markdown 文件,并返回一个包含该文件中所有链接的 URL 的数组。这个函数的类型是这样的:
func extractLinks(markdownFile: String) -> [URL]
如果我们有一系列的 Markdown 文件,并且想将这些文件中所有的链接都提取到一个单独的数组中的话,我们可以尝试使用 markdownFiles.map(extractLinks) 来构建。不过问题是这个方法返回的是一个包含了 URL 的数组的数组,这个数组中的每个元素都是一个文件中的 URL 的数组。为了得到一个包含所有 URL 的数组,你还要对这个由 map 取回的数组中的每一个数组用 joined 来进行展平 (flatten),将它归并到一个单一数组中去:
let markdownFiles: [String] = // ...
let nestedLinks = markdownFiles.map(extractLinks)
let links = nestedLinks.joined()
flatMap 将这两个操作合并为一个步骤。markdownFiles.flatMap(links) 将直接把所有 Markdown 文件中的所有 URL 放到一个单独的数组里并返回。
flatMap 的函数签名看起来也和 map 基本一致,不过 flatMap 变换函数返回的是一个数组。在实现中,它使用的是 append(contentsOf:) 而不是 append(_:),这样它将能把结果数组进行展平:
extension Array {
func flatMap<T>(_ transform: (Element) -> [T]) -> [T] {
var result: [T] = []
for x in self {
result.append(contentsOf: transform(x))
}
return result
}
}
flatMap 的另一个常见使用情景是将不同数组里的元素进行合并。为了得到两个数组中元素的所有配对组合,我们可以对其中一个数组进行 flatMap,然后对另一个进行 map 操作:
let suits = ["♠︎", "♥︎", "♣︎", "♦︎"]
let ranks = ["J","Q","K","A"]
let result = suits.flatMap { suit in
ranks.map { rank in
(suit, rank)
}
}
/*
[("♠︎", "J"), ("♠︎", "Q"), ("♠︎", "K"), ("♠︎", "A"), ("♥︎", "J"), ("♥︎",
"Q"), ("♥︎", "K"), ("♥︎", "A"), ("♣︎", "J"), ("♣︎", "Q"), ("♣︎", "K"),
("♣︎", "A"), ("♦︎", "J"), ("♦︎", "Q"), ("♦︎", "K"), ("♦︎", "A")]
*/
使用 forEach 进行迭代
我们最后要讨论的操作是 forEach。它和 for 循环的作为非常类似:传入的函数对序列中的每个元素执行一次。和 map 不同,forEach 不返回任何值。技术上来说,我们可以不暇思索地将一个 for 循环替换为 forEach:
for element in [1,2,3] {
print(element)
}
[1,2,3].forEach { element in
print(element)
}
这没什么特别之处,不过如果你想要对集合中的每个元素都调用一个函数的话,使用 forEach 会比较合适。你只需要将函数或者方法直接通过参数的方式传递给 forEach 就行了,这可以改善代码的清晰度和准确性。比如在一个 view controller 里你想把一个数组中的视图都加到当前 view 上的话,只需要写 theViews.forEach(view.addSubview) 就足够了。
不过,for 循环和 forEach 有些细微的不同,值得我们注意。比如,当一个 for 循环中有 return 语句时,将它重写为 forEach 会造成代码行为上的极大区别。让我们举个例子,下面的代码是通过结合使用带有条件的 where 和 for 循环完成的:
extension Array where Element: Equatable {
func index(of element: Element) -> Int? {
for idx in self.indices where self[idx] == element {
return idx
}
return nil
}
}
我们不能直接将 where 语句加入到 forEach 中,所以我们可能会用 filter 来重写这段代码 (实际上这段代码是错误的):
extension Array where Element: Equatable {
func index_foreach(of element: Element) -> Int? {
self.indices.filter { idx in
self[idx] == element
}.forEach { idx in
return idx
}
return nil
}
}
在 forEach 中的 return 并不能返回到外部函数的作用域之外,它仅仅只是返回到闭包本身之外,这和原来的逻辑就不一样了。在这种情况下,编译器会发现 return 语句的参数没有被使用,从而给出警告,我们可以找到问题所在。但我们不应该将找到所有这类错误的希望寄托在编译器上。
再思考一下下面这个简单的例子:
(1..<10).forEach { number in
print(number)
if number > 2 { return }
}
你可能一开始还没反应过来,其实这段代码将会把输入的数字全部打印出来。return 语句并不会终止循环,它做的仅仅是从闭包中返回。
在某些情况下,比如上面的 addSubview 的例子里,forEach 可能会比 for 循环更好。不过,因为 return 在其中的行为不太明确,我们建议大多数其他情况下不要用 forEach。这种时候,使用常规的 for 循环可能会更好。
数组类型
切片
除了通过单独的下标来访问数组中的元素 (比如 fibs[0]),我们还可以通过下标来获取某个范围中的元素。比如,想要得到数组中除了首个元素的其他元素,我们可以这么做:
let slice = fibs[1...]
slice // [1, 1, 2, 3, 5]
type(of: slice) // ArraySlice<Int>
它将返回数组的一个切片 (slice),其中包含了原数组中从第二个元素开始的所有部分。得到的结果的类型是 ArraySlice,而不是 Array。切片类型只是数组的一种表示方式,它背后的数据仍然是原来的数组,只不过是用切片的方式来进行表示。这意味着原来的数组并不需要被复制。ArraySlice 具有的方法和 Array 上定义的方法是一致的,因此你可以把它当做数组来进行处理。如果你需要将切片转换为数组的话,你可以通过把它传递给 Array 的构建方法来完成:
let newArray = Array(slice)
type(of: newArray) // Array<Int>
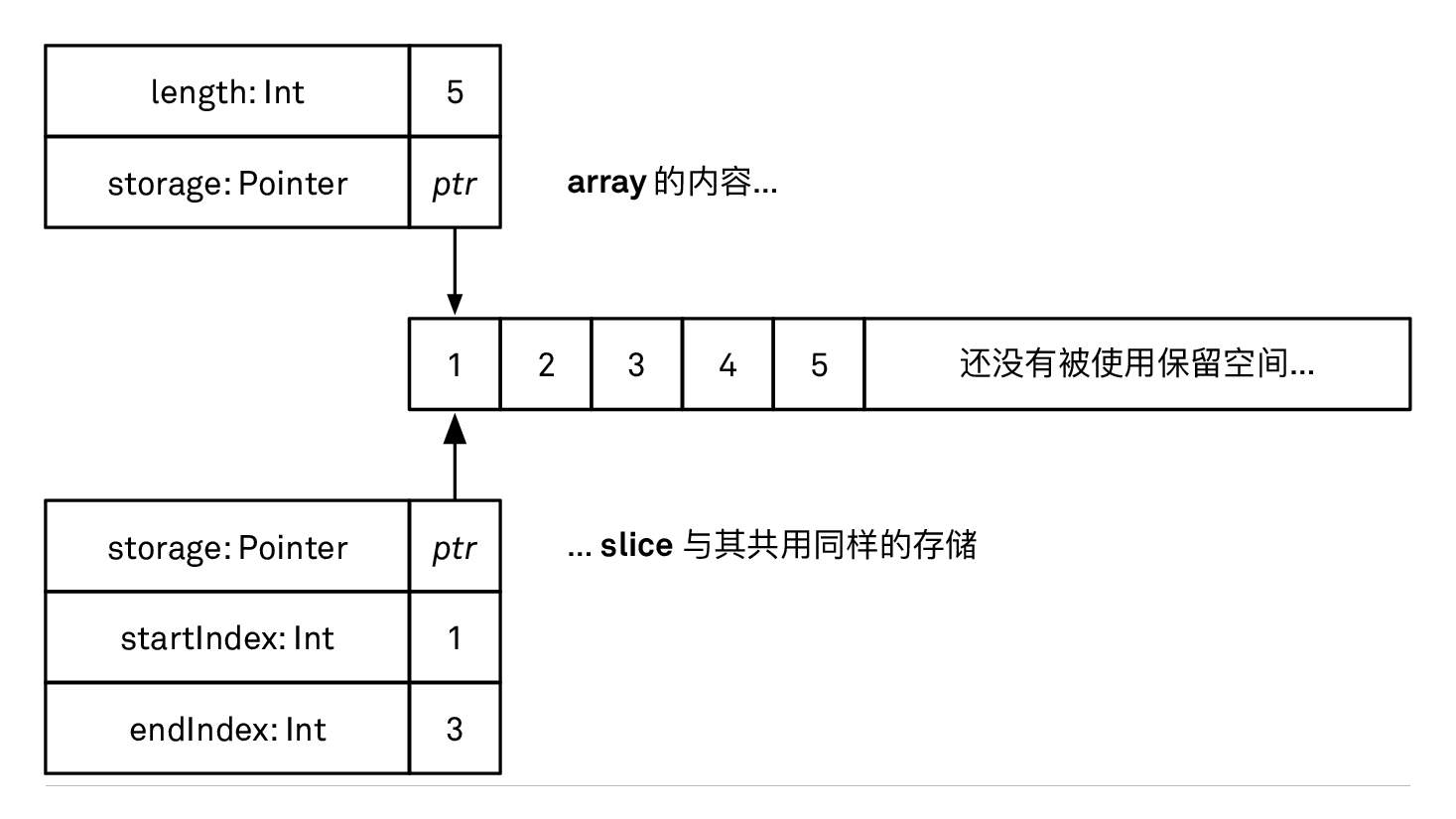
数组切片
桥接
Swift 数组可以桥接到 Objective-C 中。实际上它们也能被用在 C 代码里,不过我们稍后才会涉及到这个问题。因为 NSArray 只能持有对象,所以对 Swift 数组进行桥接转换时,编译器和运行时会自动把不兼容的值 (比如 Swift 的枚举) 用一个不透明的 box 对象包装起来。不少值类型 (比如 Int,Bool 和 String,甚至 Dictionary 和 Set) 将被自动桥接到它们在 Objctive-C 中所对应的类型。
使用统一的桥接方式来处理所有 Swift 类型到 Objective-C 的桥接工作,不仅仅使数组的处理变得容易,像是字典 (dictionary) 或者集合 (set) 这样的其他集合类型,也能从中受益。除此之外,它还为未来 Swift 与 Objective-C 之间互用性的增强带来了可能。比如,未来版本的 Swift 可能会允许一个 Swift 值类型遵守某个被标记为
@objc的协议。
字典
另一个关键的数据结构是 Dictionary。字典包含键以及它们所对应的值。在一个字典中,每个键都只能出现一次。通过键来获取值所花费的平均时间是常数量级的 (作为对比,在数组中搜寻一个特定元素所花的时间将与数组尺寸成正比)。和数组有所不同,字典是无序的,使用 for 循环来枚举字典中的键值对时,顺序是不确定的。
在下面的例子中,我们虚构一个 app 的设置界面,并使用字典作为模型数据层。这个界面由一系列的设置项构成,每一个设置项都有自己的名字 (也就是我们字典中的键) 和值。值可以是文本,数字或者布尔值之中的一种。我们使用一个带有关联值的 enum 来表示:
enum Setting {
case text(String)
case int(Int)
case bool(Bool)
}
let defaultSettings: [String:Setting] = [
"Airplane Mode": .bool(false),
"Name": .text("My iPhone"),
]
defaultSettings["Name"] // Optional(Setting.text("My iPhone"))
我们使用下标的方式可以得到某个设置的值。字典查找将返回的是可选值,当特定键不存在时,下标查询返回 nil。这点和数组有所不同,在数组中,使用越界下标进行访问将会导致程序崩溃。
从理论上来说,这个区别的原因是数组索引和字典的键的使用方式有很大不同。我们已经讨论过,对数组来说,你很少需要直接使用数组的索引。即使你用到索引,这个索引也一般是通过某些方式由数组属性计算得来的 (比如从 0..<array.count 这样的范围内获取到)。也就是说,使用一个无效索引一般都是程序员的失误。而另一方面,字典的键往往是从其他渠道得来的,从字典本身获取键反而十分少见。
与数组不同,字典是一种稀疏结构。比如,在 “name” 键下存在某个值这件事,对确定 “address” 键下是否有值毫无帮助。
可变性
和数组一样,使用 let 定义的字典是不可变的:你不能向其中添加、删除或者修改条目。如果想要定义一个可变的字典,你需要使用 var 进行声明。想要将某个值从字典中移除,可以用下标将对应的值设为 nil,或者调用 removeValue(forKey:)。后一种方法除了删除这个键以外,还会将被删除的值返回 (如果待删除的键不存在,则返回 nil)。 对于一个不可变的字典,想要进行改变的话,首先需要进行复制:
var userSettings = defaultSettings
userSettings["Name"] = .text("Jared's iPhone")
userSettings["Do Not Disturb"] = .bool(true)
再次注意,defaultSettings 的值并没有改变。和键的移除类似,除了下标之外,还有一种方法可以更新字典内容,那就是 updateValue(_:forKey:),这个方法将在更新之前有值的时候返回这个更新前的值:
let oldName = userSettings
.updateValue(.text("Jane's iPhone"), forKey: "Name")
userSettings["Name"] // Optional(Setting.text("Jane\'s iPhone"))
oldName // Optional(Setting.text("Jared\'s iPhone"))
有用的字典方法
如果我们想要将一个默认的设置字典和某个用户更改过的自定义设置字典合并,应该怎么做呢?自定义的设置应该要覆盖默认设置,同时得到的字典中应当依然含有那些没有被自定义的键值。换句话说,我们需要合并两个字典,用来做合并的字典需要覆盖重复的键。
Dictionary 有一个 merge(_:uniquingKeysWith:),它接受两个参数,第一个是要进行合并的键值对,第二个是定义如何合并相同键的两个值的函数。我们可以使用这个方法将一个字典合并至另一个字典中去,如下例所示:
var settings = defaultSettings
let overriddenSettings: [String:Setting] = ["Name": .text("Jane's iPhone")]
settings.merge(overriddenSettings, uniquingKeysWith: { $1 })
settings
// ["Name": Setting.text("Jane\'s iPhone"), "Airplane Mode": Setting.bool(false)]
在上面的例子中,我们使用了 { $1 } 来作为合并两个值的策略。也就是说,如果某个键同时存在于 settings 和 overriddenSettings 中时,我们使用 overriddenSetttings 中的值。
我们还可以从一个 (Key,Value) 键值对的序列中构建新的字典。如果我们能能保证键是唯一的,那么就可以使用 Dictionary(uniqueKeysWithValues:)。不过,对于一个序列中某个键可能存在多次的情况,就和上面一样,我们需要提供一个函数来对相同键对应的两个值进行合并。比如,要计算序列中某个元素出现的次数,我们可以对每个元素进行映射,将它们和 1 对应起来,然后从得到的 (元素, 次数) 的键值对序列中创建字典。如果我们遇到相同键下的两个值 (也就是说,我们看到了同样地元素若干次),我们只需要将次数用 + 累加起来就行了:
extension Sequence where Element: Hashable {
var frequencies: [Element:Int] {
let frequencyPairs = self.map { ($0, 1) }
return Dictionary(frequencyPairs, uniquingKeysWith: +)
}
}
let frequencies = "hello".frequencies // ["e": 1, "o": 1, "l": 2, "h": 1]
frequencies.filter { $0.value > 1 } // ["l": 2]
我们要添加的另一个有用方法是 map 函数,它可以用来操作并转换字典中的值。因为 Dictionary 已经是一个 Sequence 类型,它已经有一个 map 函数来产生数组。不过我们有时候想要的是结果保持字典的结构,只对其中的值进行映射。mapValues 方法就是做这件事的:
let settingsAsStrings = settings.mapValues { setting -> String in
switch setting {
case .text(let text): return text
case .int(let number): return String(number)
case .bool(let value): return String(value)
}
}
settingsAsStrings // ["Name": "Jane\'s iPhone", "Airplane Mode": "false"]
Hashable 要求
字典其实是哈希表。字典通过键的 hashValue 来为每个键指定一个位置,以及它所对应的存储。这也就是 Dictionary 要求它的 Key 类型需要遵守 Hashable 协议的原因。标准库中所有的基本数据类型都是遵守 Hashable 协议的,它们包括字符串,整数,浮点数以及布尔值。不带有关联值的枚举类型也会自动遵守 Hashable。
如果你想要将自定义的类型用作字典的键,那么你必须手动为你的类型添加 Hashable 并满足它,这需要你实现 hashValue 属性。另外,因为 Hashable 本身是对 Equatable 的扩展,因此你还需要为你的类型重载 == 运算符。你的实现必须保证哈希不变原则:两个同样的实例 (由你实现的 == 定义相同),必须拥有同样的哈希值。不过反过来不必为真:两个相同哈希值的实例不一定需要相等。不同的哈希值的数量是有限的,然而很多可以被哈希的类型 (比如字符串) 的个数是无穷的。
哈希值可能重复这一特性,意味着 Dictionary 必须能够处理哈希碰撞。不必说,优秀的哈希算法总是能给出较少的碰撞,这将保持集合的性能特性。理想状态下,我们希望得到的哈希值在整个整数范围内平均分布。在极端的例子下,如果你的实现对所有实例返回相同的哈希值 (比如 0),那么这个字典的查找性能将下降到 O(n)。
优秀哈希算法的第二个特质是它应该很快。记住,在字典中进行插入,移除,或者查找时,这些哈希值都要被计算。如果你的 hashValue 实现要消耗太多时间,那么它很可能会拖慢你的程序,让你从字典的 O(1) 特性中得到的好处损失殆尽。
写一个能同时做到这些要求的哈希算法并不容易。不过好消息是,我们很快在绝大部分情况下不再需要自己动手计算哈希了。一个关于自动满足 Equatable 和 Hashable 的提案已经被接受了。一旦这个特性被实现并且合并,我们就可以让编译器自动为我们的自定义类型生成满足 Equatable 和 Hashable 协议的代码。
最后,当你使用不具有值语义的类型 (比如可变的对象) 作为字典的键时,需要特别小心。如果你在将一个对象用作字典键后,改变了它的内容,它的哈希值和/或相等特性往往也会发生改变。这时候你将无法再在字典中找到它。这时字典会在错误的位置存储对象,这将导致字典内部存储的错误。对于值类型来说,因为字典中的键不会和复制的值共用存储,因此它也不会被从外部改变,所以不存在这个的问题。
Set
标准库中第三种主要的集合类型是集合 Set (虽然听起来有些别扭)。集合是一组无序的元素,每个元素只会出现一次。你可以将集合想像为一个只存储了键而没有存储值的字典。和 Dictionary 一样,Set 也是通过哈希表实现的,并拥有类似的性能特性和要求。测试集合中是否包含某个元素是一个常数时间的操作,和字典中的键一样,集合中的元素也必须满足 Hashable。
如果你需要高效地测试某个元素是否存在于序列中并且元素的顺序不重要时,使用集合是更好的选择 (同样的操作在数组中的复杂度是 O(n))。另外,当你需要保证序列中不出现重复元素时,也可以使用集合。
Set 遵守 ExpressibleByArrayLiteral 协议,也就是说,我们可以用数组字面量的方式初始化一个集合:
let naturals: Set = [1, 2, 3, 2]
naturals // [2, 3, 1]
naturals.contains(3) // true
naturals.contains(0) // false
注意数字 2 在集合中只出现了一次,重复的数字并没有被插入到集合中。
和其他集合类型一样,集合也支持我们已经见过的那些基本操作:你可以用 for 循环进行迭代,对它进行 map 或 filter 操作,或者做其他各种事情。
集合代数
正如其名,集合 Set 和数学概念上的集合有着紧密关系;Set 也支持你在高中数学中学到的那些基本集合操作。比如,我们可以在一个集合中求另一个集合的补集:
let iPods: Set = ["iPod touch", "iPod nano", "iPod mini",
"iPod shuffle", "iPod Classic"]
let discontinuedIPods: Set = ["iPod mini", "iPod Classic",
"iPod nano", "iPod shuffle"]
let currentIPods = iPods.subtracting(discontinuedIPods) // ["iPod touch"]
我们也可以求两个集合的交集,找出两个集合中都含有的元素:
let touchscreen: Set = ["iPhone", "iPad", "iPod touch", "iPod nano"]
let iPodsWithTouch = iPods.intersection(touchscreen)
// ["iPod touch", "iPod nano"]
或者,我们能求两个集合的并集,将两个集合合并为一个 (当然,移除那些重复多余的):
var discontinued: Set = ["iBook", "Powerbook", "Power Mac"]
discontinued.formUnion(discontinuedIPods)
discontinued
/*
["iBook", "Powerbook", "Power Mac", "iPod Classic", "iPod mini",
"iPod shuffle", "iPod nano"]
*/
这里我们使用了可变版本的 formUnion 来改变原来的集合 (正因如此,我们需要将原来的集合用 var 声明)。几乎所有的集合操作都有不可变版本以及可变版本的形式,后一种都以 form... 开头。想要了解更多的集合操作,可以看看 SetAlgebra 协议。
索引集合和字符集合
Set 和 OptionSet 是标准库中唯一实现了 SetAlgebra 的类型,但是这个协议在 Foundation 中还被另外两个很有意思的类型实现了:那就是 IndexSet 和 CharacterSet。两者都是在 Swift 诞生之前很久就已经存在的东西了。包括这两个类在内的其他一些 Objective-C 类现在被完全以值类型的方式导入到 Swift 中,在此过程中,它们还遵守了一些常见的标准库协议。这对 Swift 开发者来说非常友好,这些类型立刻就变得熟悉了。
IndexSet 表示了一个由正整数组成的集合。当然,你可以用 Set<Int> 来做这件事,但是 IndexSet 更加高效,因为它内部使用了一组范围列表进行实现。打个比方,现在你有一个含有 1000 个用户的 table view,你想要一个集合来管理已经被选中的用户的索引。使用 Set<Int> 的话,根据选中的个数不同,最多可能会要存储 1000 个元素。而 IndexSet 不太一样,它会存储连续的范围,也就是说,在选取前 500 行的情况下,IndexSet 里其实只存储了选择的首位和末位两个整数值。
不过,作为 IndexSet 的用户,你不需要关心这个数据结构的内部实现,所有这一切都隐藏在我们所熟知的 SetAlgebra 和 Collection 接口之下。(除非你确实需要直接操作内部的范围,对于这种需求,IndexSet 暴露了它的 rangeView 属性,代表了集合内部的范围)。举例来说,你可以向一个索引集合中添加一些范围,然后对这些索引 map 操作,就像它们是独立的元素一样:
var indices = IndexSet()
indices.insert(integersIn: 1..<5)
indices.insert(integersIn: 11..<15)
let evenIndices = indices.filter { $0 % 2 == 0 } // [2, 4, 12, 14]
同样地,CharacterSet 是一个高效的存储 Unicode 码点 (code point) 的集合。它经常被用来检查一个特定字符串是否只包含某个字符子集 (比如字母数字 alphanumerics 或者数字 decimalDigits) 中的字符。不过,和 IndexSet 有所不同,CharacterSet 并不是一个集合类型。它的名字,CharacterSet,是从 Objective-C 导入时生成的,在 Swift 中它也并不兼容 Swift 的 Character 类型。可能 UnicodeScalarSet 会是更好的名字。我们将在字符串一章中对 CharacterSet 进行更多讨论。
在闭包中使用集合
就算不暴露给函数的调用者,字典和集合在函数中也会是非常好用的数据结构。我们如果想要为 Sequence 写一个扩展,来获取序列中所有的唯一元素,我们只需要将这些元素放到一个 Set 里,然后返回这个集合的内容就行了。不过,因为 Set 并没有定义顺序,所以这么做是不稳定的,输入的元素的顺序在结果中可能会不一致。为了解决这个问题,我们可以创建一个扩展来解决这个问题,在扩展方法内部我们还是使用 Set 来验证唯一性:
extension Sequence where Element: Hashable {
func unique() -> [Element] {
var seen: Set<Element> = []
return filter { element in
if seen.contains(element) {
return false
} else {
seen.insert(element)
return true
}
}
}
}
[1,2,3,12,1,3,4,5,6,4,6].unique() // [1, 2, 3, 12, 4, 5, 6]
上面这个方法让我们可以找到序列中的所有不重复的元素,并且维持它们原来的顺序。在我们传递给 filter 的闭包中,我们使用了一个外部的 seen 变量,我们可以在闭包里访问和修改它的值。我们会在函数一章中详细讨论它背后的技术。
Range
范围代表的是两个值的区间,它由上下边界进行定义。你可以通过 ..< 来创建一个不包含上边界的半开范围,或者使用 ... 创建同时包含上下边界的闭合范围:
// 0 到 9, 不包含 10
let singleDigitNumbers = 0..<10
Array(singleDigitNumbers) // [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
// 包含 "z"
let lowercaseLetters = Character("a")...Character("z")
这些操作符还有一些前缀和后缀的变型版本,用来表示单边的范围:
let fromZero = 0...
let upToZ = ..<Character("z")
一共有八种不同的独立类型可以用来表示范围,每种类型都代表了对值的不同的约束。最常用的两种类型是 Range (由 ..< 创建的半开范围) 和 ClosedRange (由 ... 创建的闭合范围)。两者都有一个 Bound 的泛型参数:对于 Bound 的唯一的要求是它必须遵守 Comparable 协议。举例来说,上面的 lowercaseLetters 表达式的类型是 ClosedRange<Character>。出人意料的是,我们不能对 Range 或者 ClosedRange 进行迭代,但是我们可以检查某个元素是否存在于范围中:
singleDigitNumbers.contains(9) // true
lowercaseLetters.overlaps("c"..<"f") // true
(对字符范围进行迭代粗看起来应该没什么难度,但是实际却并非如此,这涉及到 Unicode 的相关知识,我们会在关于字符串的章节中再深入这个问题。)
半开范围和闭合范围各有所用:
只有半开范围能表达空间隔 (也就是下界和上界相等的情况,比如
5..<5)。只有闭合范围能包括其元素类型所能表达的最大值 (比如
0...Int.max)。而半开范围则要求范围上界是一个比自身所包含的最大值还要大 1 的值。
可数范围
范围看起来很自然地会是一个序列或者集合类型,但是可能出乎你的意料,Range 和 ClosedRange 既非序列,也不是集合类型。有一部分范围确实是序列,不然的话,我们就不能实现在 for 循环中对于一个整数范围进行迭代了:
for i in 0..<10 {
print("\(i)", terminator: " ")
} // 0 1 2 3 4 5 6 7 8 9
之所以能这样做的原因,是因为 0..<10 的类型其实是一个 CountableRange<Int>。CountableRange 和 Range 很相似,只不过它还需要一个附加约束:它的元素类型需要遵守 Strideable 协议 (以整数为步长)。Swift 将这类功能更强的范围叫做可数范围,这是因为只有这类范围可以被迭代。可数范围的边界可以是整数或者指针类型,但不能是浮点数类型,这是由于 Stride 类型中有一个整数的约束。如果你想要对连续的浮点数值进行迭代的话,你可以通过使用 stride(from:to:by) 和 stride(from:through:by) 方法来创建序列用以迭代。Strideable 的约束使得 CountableRange 和 CountableClosedRange 遵守 RandomAccessCollection,于是我们就能够对它们进行迭代了。
到目前为止,我们讨论过的范围类型可以被归类到下面这个 2x2 的矩阵中:
| 半开范围 | 闭合范围 | |
|---|---|---|
元素满足 Comparable |
Range |
ClosedRange |
元素满足 Strideable |
CountableRange |
CountableClosedRange |
| (以整数为步长) |
上表中的行对范围的类型进行了区分,如果元素类型仅仅只是满足 Comparable,它对应的是“普通”范围 (这是范围元素的最小要求),那些元素满足 Strideable,并且使用整数作为步长的范围则是可数范围。只有后一种范围是集合类型,它继承了我们在下一章中将要看到的一系列强大的功能。
部分范围
部分范围 (partial range) 指的是将 ... 或 ..< 作为前置或者后置运算符来使用时所构造的范围。比如,0... 表示一个从 0 开始的范围。这类范围由于缺少一侧的边界,因此被称为部分范围。具体来说,有四种不同的部分范围:
let fromA: PartialRangeFrom<Character> = Character("a")...
let throughZ: PartialRangeThrough<Character> = ...Character("z")
let upto10: PartialRangeUpTo<Int> = ..<10
let fromFive: CountablePartialRangeFrom<Int> = 5...
其中能够计数的只有 CountablePartialRangeFrom 这一种类型,四种部分范围类型中,只有它能被进行迭代。迭代操作会从 lowerBound 开始,不断重复地调用 advanced(by: 1)。如果你在一个 for 循环中使用这种范围,你必须牢记要为循环添加一个 break 的退出条件,否则循环将无限进行下去 (或者当计数溢出的时候发生崩溃)。PartialRangeFrom 不能被迭代,这是因为它的 Bound 不满足 Strideable。而 PartialRangeThrough 和 PartialRangeUpTo 则是因为没有下界而无法开始迭代。
范围表达式
所有这八种范围都满足 RangeExpression 协议。这个协议内容很简单,所以我们可以将它列举到书里。首先,它允许我们询问某个元素是否被包括在该范围中。其次,给定一个集合类型,它能够计算出表达式所指定的完整的 Range:
public protocol RangeExpression {
associatedtype Bound: Comparable
func contains(_ element: Bound) -> Bool
func relative<C: _Indexable>(to collection: C) -> Range<Bound>
where C.Index == Bound
}
对于下界缺失的部分范围,relative(to:) 方法会把集合类型的 startIndex 作为范围下界。对于上界缺失的部分范围,同样,它会使用 endIndex 作为上界。这样一来,部分范围就能使集合切片的语法变得相当紧凑:
let arr = [1,2,3,4]
arr[2...] // [3, 4]
arr[..<1] // [1]
arr[1...2] // [2, 3]
这种写法能够正常工作,是因为 Collection 协议里对应的下标操作声明中,所接收的是一个 RangeExpression 的参数,而不是上述八个具体的范围类型中的某一个。你甚至还可以将两个边界都省略掉,这样你将会得到整个集合类型的切片:
arr[...] // [1, 2, 3, 4]
type(of: arr) // Array<Int>
(这其实是 Swift 4.0 标准库中的一个特殊实现,这种无界范围还不是有效的 RangeExpression 类型,不过它应该会在今后遵守 RangeExpression 协议。)
范围和按条件遵守协议
现在,标准库必须将可数范围区分为 CountableRange,CountableClosedRange 和 CountablePartialRangeFrom。在理想情况下,它们不应该是独立的类型,而只需要分别对 Range,ClosedRange 和 PartialRangeFrom 进行扩展,让它们在泛型参数满足所需要求的条件下,遵守 Collection 协议。我们将在下一章对该话题进行更多的讨论,定义这样的扩展的代码如下:
// Swift 4 中无法做到
extension Range: RandomAccessCollection
where Bound: Strideable, Bound.Stride: SignedInteger
{
// 实现 RandomAccessCollection
}
啊咧,Swift 4 的类型系统并不支持这样的表达方式,你还不能为特定的泛型参数条件添加扩展,所以这里我们只能使用另外的类型。对于按照条件进行扩展的支持有望在 Swift 5 中被加入,届时 CountableRange 和 CountableClosedRange 和 CountablePartialRangeFrom 将会被弃用并从标准库中移除。
半开的 Range 和闭合的 ClosedRange 之间的差异应该会一直存在,这个差异有时候会使得对范围的使用变得十分困难。比如说你有一个方法接受 Range<Character> 作为参数,而同时你想要将我们上面创建的闭合的字符范围传递给它。这时候你会惊奇地发现,这是不可能完成的任务!可能你无法解释,为什么没有一种方法将 ClosedRange 转换为 Range 呢?如果想要将一个闭合范围转换为等效的半开范围,那么你就需要找到原来的闭合范围上界的后一个元素。只有当元素本身满足 Strideable 时,这才是可能的。而只有可数范围才为元素满足 Strideable 这一条件提供保证。
也就是说,这个函数的调用者必须提供合适的类型。如果一个函数接受 Range 作为参数,那么你就不能用 ... 来创建它。在实践中,我们不太确定这会带来多大的限制,因为大部分的范围都是基于整数的,不过可以肯定的是,这不太符合我们的直觉。
在可能的情况下,我们可以照抄标准库的做法,为你自己的函数提供一个 RangeExpression 参数,而不是某个具体的类型。有时候我们不能这么做,因为该协议只有在你提供了一个集合类型上下文的时候,才能给出范围的边界。不过如果集合类型这个条件能被满足,那么 API 的使用者就可以通过传入任意类型的范围表达式来进行调用了,这提供了一个更加自由的方式。
回顾
在本章中,我们介绍了一系列不同的集合类型:数组,字典,Set,IndexSet 和范围。我们还研究了这些集合类型的一些方法。在下一章,我们会看到这些方法中的大部分都是在 Sequence 协议中定义的。我们还知道了 Swift 内建的集合类型允许你使用 let 和 var 来控制集合的可变性。另外,我们也对各种不同的 Range 类型进行了介绍。
集合类型协议
在前一章中,我们看到了 Array,Dictionary 和 Set,它们并非空中楼阁,而是建立在一系列由 Swift 标准库提供的用来处理元素序列的抽象之上的。这一章我们将讨论 Sequence 和 Collection 协议,它们构成了这套集合类型模型的基石。我们会研究这些协议是如何工作的,它们为什么要以这样的方式工作,以及你如何写出自己的序列和集合类型等话题。
序列
Sequence 协议是集合类型结构中的基础。一个序列 (sequence) 代表的是一系列具有相同类型的值,你可以对这些值进行迭代。遍历一个序列最简单的方式是使用 for 循环:
for element in someSequence {
doSomething(with: element)
}
Sequence 协议提供了许多强大的功能,满足该协议的类型都可以直接使用这些功能。上面这样步进式的迭代元素的能力看起来十分简单,但它却是 Sequence 可以提供这些强大功能的基础。我们已经在上一章提到过不少这类功能了,每当你遇到一个能够针对元素序列进行的通用的操作,你都应该考虑将它实现在 Sequence 层的可能性。在本章和书中接下来的部分,我们将会看到许多这方面的例子。
满足 Sequence 协议的要求十分简单,你需要做的所有事情就是提供一个返回迭代器 (iterator) 的 makeIterator() 方法:
protocol Sequence {
associatedtype Iterator: IteratorProtocol
func makeIterator() -> Iterator
// ...
}
对于迭代器,我们现在只能从 Sequence 的 (这个简化后的) 定义中知道它是一个可以创建迭代器 (Iterator) 协议的类型。所以我们首先来仔细看看迭代器是什么。
集合类型
遵守 Collection 协议
索引
切片
专门的集合类型
回顾
可选值
哨岗值
在编程世界中有一种非常通用的模式,那就是某个操作是否要返回一个有效值。
当你在读取文件并读到文件末尾时,也许期望的是不返回值,就像下面的 C 代码这样:
int ch;
while ((ch = getchar()) != EOF) {
printf("Read character %c\n", ch);
}
printf("Reached end-of-file\n");
EOF 只是对于 -1 的一个 #define。如果文件中还有其他字符,getchar 将会返回它们。如果到达文件末尾,getchar 将返回 -1。
又或者返回空值意味着“未找到”,就像 C++ 中的那样:
auto vec = {1, 2, 3};
auto iterator = std::find(vec.begin(), vec.end(), someValue);
if (iterator != vec.end()) {
std::cout << "vec contains " << *iterator << std::endl;
}
在这里,vec.end() 是容器的“末尾再超一位”的迭代器。这是一个特殊的迭代器,你可以用它来检查容器末尾,但是和 Swift 集合类型中的 endIndex 类似,你不能实际用它来获取这个值。find 使用它来表达容器中没有这样的值。
再或者,是因为函数处理过程中发生了某些错误,而导致没有值能被返回。其中,最臭名昭著的例子大概就是 null 指针了。下面这句看起来人畜无害的 Java 代码就将抛出一个 NullPointerException:
int i = Integer.getInteger("123")
因为实际上 Integer.getInteger 做的事情并不是将字符串解析为整数,它实际上会去尝试获取一个叫做 “123” 的系统属性的整数值。因为系统中并不存在这样的属性,所以 getInteger 返回的是 null。当 null 被自动解开成一个 int 时,Java 将抛出异常。
这里还有一个 Objective-C 的例子:
[[NSString alloc] initWithContentsOfURL:url
encoding:NSUTF8StringEncoding error:&e];
在这里,NSString 有可能是 nil,在这种情况下 — 而且只有在这种情况下 — 你应该去检查错误指针。如果得到的 NSString 是非 nil 的话,错误指针并不一定会是有效值。
在上面所有例子中,这些函数都返回了一个“魔法”数来表示函数并没有返回真实的值。这样的值被称为“哨岗值”。
不过这种策略是有问题的。返回的结果不管从哪个角度看都很像一个真实值。-1 的 int 值依然是一个有效的整数,但是你并不会想将它打印出来。v.end() 是一个迭代器,但是当你使用它的时候,结果却是未定义的。另外,所有人都会把你那陷于 NullPointerException 困境之中的 Java 程序当作一段笑话来看待。
和 Java 不同,Objective-C 允许我们向 nil 发送消息。这种行为是“安全”的,因为 Objective-C 在运行时会保证向 nil 发送消息时,返回值总是等价于 0,比如,如果这个消息签名返回一个对象,那么 nil 会被返回;如果是数值类型,0 会被返回。如果消息返回的是一个结构体,那么它的值都将被初始化为零。不过,让我们来看看下面这个例子:
NSString *someString = ...;
if ([someString rangeOfString:@"Swift"].location != NSNotFound) {
NSLog(@"Someone mentioned Swift!");
}
如果 someString 是 nil,那么 rangeOfString: 消息将返回一个值都为零的 NSRange。也就是说,.location 将为零,而 NSNotFound 被定义为 NSIntegerMax。这样一来,当 someString 是 nil 时,if 语句的内容将被执行,而其实这并不应该发生。
Tony Hoare 在 1965 年设计了 null 引用,他对此设计表示痛心疾首,并将这个问题称为“价值十亿美元的错误”:
那时候,我正在为一门面向对象语言 (ALGOL W) 设计第一个全面的引用类型系统。我的目标是在编译器自动执行的检查的保证下,确保对于引用的所有使用都是安全的。但是我没能抵挡住引入 null 引用的诱惑,因为它太容易实现了。这导致了不计其数的错误,漏洞以及系统崩溃。这个问题可能在过去四十年里造成了有十亿美元的损失。
可见,哨岗值很容易产生问题,因为你可能会忘记检查哨岗值,并且会不小心使用它们。使用它们还需要预先的知识。有时候会有像是 C++ 的 end 迭代器这样的约定俗成的用法,有时候又没有这种约定。你通常需要查看文档才能知道需要怎么做。另外,一个函数也没有办法来表明自己不会失败。也就是说,当一个函数的调用返回指针时,这个指针有可能绝对不会是 nil。但是除了阅读文档之外,你并没有办法能知道这个事实。更甚者有可能文档本身就是错的。
通过枚举解决魔法数的问题
可选值概览
强制解包的时机
多灾多难的隐式解包可选值
回顾
结构体和类
在 Swift 中,要存储结构化的数据,我们有多种不同的选择:结构体、枚举、类以及使用闭包捕获变量。在 Swift 标准库中,绝大多数的公开类型都是结构体,而枚举和类只占很小一部分。这可能是标准库中那些类型的特性使然,但是不管从什么方面这个事实都提醒我们 Swift 中结构体有多么重要。许多 Foundation 框架中的类现在有专门针对 Swift 构建的对应结构体类型了。在本章中,我们主要来看看结构体和类有哪些区别。我们可能不会花太多精力在枚举类型上,因为它的行为和结构体十分相似。
这里是结构体和类的主要不同点:
结构体 (和枚举) 是值类型,而类是引用类型。在设计结构体时,我们可以要求编译器保证不可变性。而对于类来说,我们就得自己来确保这件事情。
内存的管理方式有所不同。结构体可以被直接持有及访问,但是类的实例只能通过引用来间接地访问。结构体不会被引用,但是会被复制。也就是说,结构体的持有者是唯一的,但是类的实例却能有很多个持有者。
使用类,我们可以通过继承来共享代码。而结构体 (以及枚举) 是不能被继承的。想要在不同的结构体或者枚举之间共享代码,我们需要使用不同的技术,比如像是组合、泛型以及协议扩展等。
在本章中,我们将会探索这些不同之处的细节。我们会从实体和值的区别谈起,然后继续讨论可变性所带来的问题。之后,我们会向你展示如何将一个引用类型封装到结构体里,这样我们就能够把它当作一个值类型来使用。最后,我们会详细谈谈两者之间内存管理上的差异,特别是引用类型与闭包一起使用时内存的管理方式的问题,以及如何避免引用循环。
值类型
可变性
结构体
写时复制
闭包和可变性
内存
闭包和内存
回顾
编码和解码
将程序内部的数据结构序列化为一些可交换的数据格式,以及反过来将通用的数据格式反序列化为内部使用的数据结构,这在编程中是一项非常常见的任务。Swift 将这些操作称为编码 (encoding) 和解码 (decoing)。Swift 4 的一个主要特性就是定义了一套标准的编码和解码数据的方法,所有的自定义类型都能选择使用这套方法。
概览
Codable 系统 (以其基本“协议”命名,而这个协议其实是一个类型别名) 的设计主要围绕三个核心目标;
普遍性 - 它对结构体,枚举和类都适用。
类型安全 - 像是 JSON 这样的可交换格式通常都是弱类型,而你的代码应该要使用强类型数据。
减少模板代码 - 在让自定义类型加入这套系统时,应该让开发者尽可能少地写重复的“适配代码”。编译器应该为你自动生成这些代码。
某个类型通过声明自己遵守 Encodable 和/或 Decodable 协议来表明自己具备被序列化和/或反序列化的能力。这两个协议各自只有一个必须实现的方法 - Encodable 定义了 encode(to:) 用来对值自身进行编码,Decodable 指定了一个初始化方法,来从序列化的数据中创建实例:
/// 某个类型可以将自身编码为一种外部表示。
public protocol Encodable {
/// 将值编码到给定的 encoder 中。
public func encode(to encoder: Encoder) throws
}
/// 某个类型可以从外部表示中解码得到自身。
public protocol Decodable {
/// 通过从给定的 decoder 中解码来创建新的实例。
public init(from decoder: Decoder) throws
}
因为大多数实现了其中一个协议的类型,也会实现另一个,所以标准库中还提供了 Codable 类型别名,来作为这两个协议组合后的简写:
public typealias Codable = Decodable & Encodable
标准库中包括 Bool,数值类型和 String 等所有基本类型,都直接是 Codable 类型。那些含有 Codable 元素的可选值,数组,字典和集合,也都满足 Codable。最后,包括 Data,Date,URL,CGPoint 和 CGRect 在内的许多 Apple 框架中的常用数据类型,也已经适配了 Codable。
一旦你拥有一个 codable 类型的值,你就可以创建一个编码器,并让它将这个值转换到像是 JSON 这样的目标格式。反过来,一个解码器可以将序列化后的数据转回为它原来类型的一个实例。在表面上,对应的 Encoder 和 Decoder 协议并没有比 Encodable 和 Decodable 复杂太多。编码器和解码器的核心任务是管理那些用来存储序列后的数据的容器的层次。除非你想要创建自己的编解码器,否则你很少有需要和 Encoder 及 Decoder 协议直接打交道,不过,如果你想要自定义你自己类型的编解码过程,理解这些结构以及三种类型的容器还是有比较的。我们会在下面看到很多例子。
最小的例子
编码过程
生成的代码
手动遵守协议
常见的编码任务
回顾
函数
在开始本章之前,我们先来回顾一下关于函数的事情。如果你已经对头等函数 (first-class function) 的概念很熟悉了的话,你可以直接跳到下一节。但是如果你对此还有些懵懵懂懂的话,可以浏览一下这些内容。
要理解 Swift 中的函数和闭包,你需要切实弄明白三件事情,我们把这三件事按照重要程度进行了大致排序:
函数可以像
Int或者String那样被赋值给变量,也可以作为另一个函数的输入参数,或者另一个函数的返回值来使用。函数能够捕获存在于其局部作用域之外的变量。
有两种方法可以创建函数,一种是使用
func关键字,另一种是{ }。在 Swift 中,后一种被称为闭包表达式。
有时候新接触闭包的人会认为重要顺序是反过来的,或者是遗漏其中的某点,或者把闭包和闭包表达式弄混淆了,这确实有时候会很让人迷惑。然而三者鼎足而立,互为补充,如果你少了其中任何一条,那么整个架构将不复存在。
1. 函数可以被赋值给变量,也能够作为函数的输入和输出
在 Swift 和其他很多现代语言中,函数被称为“头等对象”。你可以将函数赋值给变量,稍后,你可以将它作为参数传入给要调用的函数,函数也可以返回一个函数。
这一点是我们需要理解的最重要的东西。在函数式编程中明白这一点,就和在 C 语言中明白指针的概念一样。如果你没有牢牢掌握这部分的话,其他所有东西都将是镜花水月。
这里有一个将函数赋值给变量并将它传递给其他函数的例子:
// 这个函数接受 Int 值并将其打印
func printInt(i: Int) {
print("you passed \(i)")
}
要将函数赋值给一个变量,比如 funVar,我们只需要将函数名字作为值就可以了。注意在函数名后没有括号:
let funVar = printInt
现在,我们可以使用 funVar 变量来调用 printInt 函数。注意在函数名后面需要使用括号:
funVar(2) // you passed 2
这里值得注意的是,我们不能在 funVar 调用时包含参数标签,而在 printInt 的调用 (像是 printInt(i: 2)) 却要求有参数标签。Swift 只允许在函数声明中包含标签,这些标签不是函数类型的一部分。也就是说,现在你不能将参数标签赋值给一个类型是函数的变量,不过这在未来的 Swift 版本中可能会有改变。
我们也能够写出一个接受函数作为参数的函数:
func useFunction(function: (Int) -> () ) {
function(3)
}
useFunction(function: printInt) // you passed 3
useFunction(function: funVar) // you passed 3
为什么将函数作为变量来处理这件事情如此关键?因为它让你很容易写出“高阶”函数,高阶函数将函数作为参数的能力使得它们在很多方面都非常有用,我们已经在内建集合中看到过它的威力了。
函数也可以返回其他函数:
func returnFunc() -> (Int) -> String {
func innerFunc(i: Int) -> String {
return "you passed \(i)"
}
return innerFunc
}
let myFunc = returnFunc()
myFunc(3) // you passed 3
2. 函数可以捕获存在于它们作用范围之外的变量
当函数引用了在函数作用域外部的变量时,这个变量就被“捕获”了,它们将会继续存在,而不是在超过作用域后被摧毁。
为了研究这一点,我们再来看看 returnFunc 函数。这次我们添加了一个计数器,每次我们调用这个函数时,计数器将会增加。
func counterFunc() -> (Int) -> String {
var counter = 0
func innerFunc(i: Int) -> String {
counter += i // counter is captured
return "running total: \(counter)"
}
return innerFunc
}
一般来说,因为 counter 是一个 counterFunc 的局部变量,它在 return 语句执行之后应该离开作用域并被摧毁。但是因为 innerFunc 捕获了它,所以 Swift 运行时将为一直保证它存在,直到捕获它函数被销毁为止。我们在结构体和类讨论过,counter 将存在于堆上而非栈上。我们可以多次调用 innerFunc,并且看到 running total 的输出在增加:
let f = counterFunc()
f(3) // running total: 3
f(4) // running total: 7
如果我们再次调用 counterFunc() 函数,将会生成并“捕获”新的 counter 变量:
let g = counterFunc()
g(2) // running total: 2
g(2) // running total: 4
这不影响我们的第一个函数,它拥有它自己的 counter:
f(2) // running total: 9
你可以将这些函数以及它们所捕获的变量想象为一个类的实例,这个类拥有一个单一的方法 (也就是这里的函数) 以及一些成员变量 (这里的被捕获的变量)。
在编程术语里,一个函数和它所捕获的变量环境组合起来被称为闭包。上面 f 和 g 都是闭包的例子,因为它们捕获并使用了一个在它们外部声明的非局部变量 counter。
3. 函数可以使用 { } 来声明为闭包表达式
在 Swift 中,定义函数的方法有两种。一种是使用 func 关键字。另一种方法是使用闭包表达式。下面这个简单的函数将会把数字翻倍:
func doubler(i: Int) -> Int {
return i * 2
}
[1, 2, 3, 4].map(doubler) // [2, 4, 6, 8]
使用闭包表达式的语法来写相同的函数,像之前那样将它传给 map:
let doublerAlt = { (i: Int) -> Int in return i*2 }
[1, 2, 3, 4].map(doublerAlt) // [2, 4, 6, 8]
使用闭包表达式来定义的函数可以被想成函数的字面量,就和 1 是整数字面量,"hello" 是字符串字面量那样。与 func 相比较,它的区别在于闭包表达式是匿名的,它们没有被赋予一个名字。使用它们的方式只有在它们被创建时将其赋值给一个变量,就像我们这里对 doubler > 进行的赋值一样,或者是将它们传递给另一个函数或方法。
其实还有第三种使用匿名函数的方法:你可以在定义一个表达式的同时,对它进行调用。这个方法在定义那些初始化时代码多余一行的属性时会很有用。我们将在下面的延迟属性部分看到一个例子。
使用闭包表达式声明的 doubler,和之前我们使用 func 关键字声明的函数,除了在处理我们上面提到的参数标签上略有不同以外,其实是完全等价的。它们甚至存在于同一个“命名空间”中,这一点和一些其他语言有所不同。
那么 { } 语法有什么用呢?为什么不每次都使用 func 呢?因为闭包表达式可以简洁得多,特别是在像是 map 这样的将一个快速实现的函数传递给另一个函数时,这个特点更为明显。这里,我们将 doubler map 的例子用短得多的形式进行了重写:
[1, 2, 3].map { $0 * 2 } // [2, 4, 6]
之所以看起来和原来很不同,是因为我们使用了 Swift 中的一些特性,来让代码更加简洁。我们来一个个看看这些用到的特性:
如果你将闭包作为参数传递,并且你不再用这个闭包做其他事情的话,就没有必要现将它存储到一个局部变量中。可以想象一下比如
5*i这样的数值表达式,你可以把它直接传递给一个接受Int的函数,而不必先将它计算并存储到变量里。如果编译器可以从上下文中推断出类型的话,你就不需要指明它了。在我们的例子中,从数组元素的类型可以推断出传递给
map的函数接受Int作为参数,从闭包的乘法结果的类型可以推断出闭包返回的也是Int。如果闭包表达式的主体部分只包括一个单一的表达式的话,它将自动返回这个表达式的结果,你可以不写
return。Swift 会自动为函数的参数提供简写形式,
$0代表第一个参数,$1代表第二个参数,以此类推。如果函数的最后一个参数是闭包表达式的话,你可以将这个闭包表达式移到函数调用的圆括号的外部。这样的尾随闭包语法在多行的闭包表达式中表现非常好,因为它看起来更接近于装配了一个普通的函数定义,或者是像
if (expr) { }这样的执行块的表达形式。最后,如果一个函数除了闭包表达式外没有别的参数,那么方法名后面的调用时的圆括号也可以一并省略。
依次将上面的每个规则使用到最初的表达式里,我们可以逐步得到最后的结果:
[1, 2, 3].map( { (i: Int) -> Int in return i * 2 } )
[1, 2, 3].map( { i in return i * 2 } )
[1, 2, 3].map( { i in i * 2 } )
[1, 2, 3].map( { $0 * 2 } )
[1, 2, 3].map() { $0 * 2 }
[1, 2, 3].map { $0 * 2 }
如果你刚接触 Swift 的语法,或者刚接触函数式编程的话,这些精简的函数表达第一眼看起来可能让你丧失信心。但是一旦你习惯了这样的语法以及函数式编程的风格的话,它们很快就会看起来很自然,移除这些杂乱的表达,可以让你对代码实际做的事情看得更加清晰,你一定会为语言中有这样的特性而心存感激。一旦你习惯了阅读这样的代码,你一眼就能看出这段代码做了什么,而想在一个等效的 for 循环中做到这一点则要困难得多。
有时候,Swift 可能需要你在类型推断的时候给一些提示。还有某些情况下,你可能会得到和你想象中完全不同的错误类型。如果你在尝试提供闭包表达式时遇到一些谜一样的错误的话,将闭包表达式写成上面例子中的第一种包括类型的完整形式,往往会是个好主意。在很多情况下,这有助于厘清错误到底在哪儿。一旦完整版本可以编译通过,你就可以逐渐将类型移除,直到编译无法通过。如果造成错误的是你的其他代码的话,在这个过程中相信你已经修复好这些代码了。
Swift 有时候会要求你用更明显的方式进行调用。比如,你不能完全省略掉输入参数。假设你想要一组随机数的数组,一种快速的方式是对一个范围进行 map 操作,在 map 中生成一个随机数。但无论如何你还是要为 map 接受的函数提供一个输入参数。在这里,你可以使用单下划线 _ 来告诉编译器你承认这里有一个参数,但是你并不关心它究竟是什么:
(0..<3).map { _ in arc4random() } // [3947060353, 2319782664, 1209325014]
当你需要显式地指定变量类型时,你不一定要在闭包表达式内部来设定。比如,让我们来定义一个 isEven,它不指定任何类型:
let isEven = { $0 % 2 == 0 }
在上面,isEven 被推断为 Int -> Bool。这和 let i = 1 被推断为 Int 是一个道理,因为 Int 是整数字面量的默认类型。
这是因为标准库中的
IntegerLiteralType有一个类型别名:protocol ExpressibleByIntegerLiteral { associatedtype IntegerLiteralType /// 用 `value` 创建一个实例。 init(integerLiteral value: Self.IntegerLiteralType) } /// 一个没有其余类型限制的整数字面量的默认类型。 typealias IntegerLiteralType = Int如果你想要定义你自己的类型别名,你可以重写默认值来改变这一行为:
typealias IntegerLiteralType = UInt32 let i = 1 // i 的类型为 UInt32.显然,这不是一个什么好主意。
不过,如果你需要 isEven 是别的类型的话,你也可以为参数和闭包表达式中的返回值指定类型:
let isEvenAlt = { (i: Int8) -> Bool in i % 2 == 0 }
你也可以在闭包外部的上下文里提供这些信息:
let isEvenAlt2: (Int8) -> Bool = { $0 % 2 == 0 }
let isEvenAlt3 = { $0 % 2 == 0 } as (Int8) -> Bool
因为闭包表达式最常见的使用情景就是在一些已经存在输入或者输出类型的上下文中,所以这种写法并不是经常需要,不过知道它还是会很有用。
函数的灵活性
局部函数和变量捕获
函数作为代理
inout 参数和可变方法
计算属性
下标
键路径
自动闭包
回顾
字符串
所有的现在编程语言都支持 Unicode 字符串,但是通常这只意味着原生的字符串类型可以存储 Unicode 数据 - 它没有保证像是获取字符串长度这类简单操作会返回“恰当”的结果。实际上,大部分语言,以及用这些语言所写的对字符串进行操作的代码,都在某种程度上展现出了对 Unicode 内在复杂度的抗拒。这可能会造成一些令人不快 bug。
Swift 在字符串实现上做出了英勇的努力,它力求尽可能做到 Unicode 正确。Swift 中的 String 是 Character 值的集合,而 Character 是人类在阅读文字时所理解的单个字符,这与该字符由多少个 Unicode 码点组成无关。这样一来,像是 count 或者 prefix(5) 在内的所有标准的 Collection 操作都会在用户所理解的字符这个层级上工作。
这对于正确性来说非常重要,但是也有所代价。大部分代价来源于开发者对这套规则的不熟悉。如果你在其他语言中用整数作为索引操作过字符串,那么 Swift 的设计一开始可能看起来非常笨重。你可能会想,为什么我不能用 str[999] 来获取字符串的第一千个字符?为什么 str[idx+1] 不能访问到下一个字符?为什么我不能在 "a"..."z" 这样的 Character 的值所构成的范围中进行循环?同样,还有一些性能上的影响:String 不支持随机访问,也就是说,跳到字符串中某个随机的字符不是一个 O(1) 操作。当字符拥有可变宽度时,字符串并不知道第 n 个字符到底存储在哪儿,它必须查看这个字符前面的所有字符,才能最终确定对象字符的存储位置,所以这不可能是一个 O(1) 操作。
在本章中,我们会深入讨论字符串的架构,我们也会涉及如何发挥 Swift 字符串的功能,以及保持良好性能的话题。不过,我们需要先从了解一些 Unicode 术语的总览开始。
Unicode,而非固定宽度
事情原本很简单。ASCII 字符串就是由 0 到 127 之间的整数组成的序列。如果你把这种整数放到一个 8 比特的字节里,你甚至还能省出一个比特。由于每个字符宽度都是固定的,所以 ASCII 字符串可以被随机存取。
但是对于非英语的文字,或者受众不是美国人的时候,ASCII 编码就不够了。其他国家和语言需要不一样的字符 (就连同样说英语的英国人都需要一个表示英镑的 £ 符号),其中绝大多数需要的字符用七个比特是放不下的。ISO/IEC 8859 使用了额外的第八个比特,并且在 ASCII 范围外又定义了 16 种不同的编码。比如第 1 部分 (ISO/IEC 8859-1,又叫 Latin-1),涵盖多种西欧语言;以及第 5 部分,涵盖那些使用西里尔 (俄语) 字母的语言。
但是这样依然很受限。如果你想按照 ISO/IEC 8859 来用土耳其语书写关于古希腊的内容,那你就不怎么走运了。因为你只能在第 7 部分 (Latin/Greek) 或者第 9 部分 (Turkish) 中选一种。另外,八个比特对于许多语言的编码来说依然是不够的。比如第 6 部分 (Latin/Arabic) 没有包括书写乌尔都语或者波斯语这样的阿拉伯字母语言所需要的字符。同时,在从 ASCII 的下半区替换了少量字符后,我们才能用八比特去编码基于拉丁字母但同时又有大量变音符组合的越南语。而其他东亚语言则完全不能被放入八个比特中。
当固定宽度的编码空间被用完后,你有两种选择:选择增加宽度或者切换到可变长的编码。最初的时候,Unicode 被定义成两个字节固定宽度的格式,这种格式现在被称为 UCS-2。不过这已经是现实问题出现之前的决定了,而且大家也都承认其实两个字节也还是不够用,四个字节的话在大多数情况下又太低效。
所以今天的 Unicode 是一个可变长格式。它的可变长特性有两种不同的意义:由编码单元 (code unit) 组成 Unicode 标量 (Unicode scalar);由 Unicode 标量组成字符。
Unicode 数据可以被编码成许多不同宽度的编码单元,最普遍的使用的是 8 比特 (UTF-8) 或者 16 比特 (UTF-16) 。UTF-8 额外的优势在于可以向后兼容 8 比特的 ASCII。这也使其超过 ASCII 成为网上最流行的编码方式。Swift 将 UTF-16 和 UTF-8 的编码单元分别用 UInt16 和 UInt8 来表示 (它们被赋予了 Unicode.UTF16.CodeUnit 和 Unicode.UTF8.CodeUnit 的类型别名)。
Unicode 中的编码点 (code point) 在 Unicode 编码空间中是介于 0 到 0x10FFFF (也就是十进制的 1,114,111) 之间的一个单一值。在这 110 万个数值里,现在只有大约 137,000 个在被使用中,还有很多空间可以用来存放颜文字这样的东西。对于 UTF-32,一个编码点会占用一个编码单元。对于 UTF-8 一个编码点会占用一至四个编码单元。起始的 256 个 Unicode 编码点和 Latin-1 中的字符是一致的。
Unicode 标量和编码点在大部分情况下是同样的东西。除了在 0xD800–0xDFFF 之间范围里的 2,048 个“代理” (surrogate) 编码点 (它们被用来标示成对的 UTF-16 编码的开头或者结尾) 之外的所有编码点,都是 Unicode 标量。标量在 Swift 字符串字面量中以 "\u{xxxx}" 来表示,其中的 xxxx 是十六进制的数字。比如欧元符号 € 在 Swift 中写作 "\u{20AC}"。Unicode 标量在 Swift 中对应的类型是 Unicode.Scalar,它是一个对 UInt32 的封装类型。
要用单个的编码单元来对应一个 Unicode 标量的话,你需要一个 21 位的编码系统 (通常它会被向上“取整”到 32 位,也就是 UTF-32),不过即使这样,编码的宽度也不是固定的:在用标量组成“字符”时,Unicode 依旧是一个可变宽度的格式。用户所认为的在屏幕上显示的“单个字符”可能仍需要由多个编码点组合而成。在 Unicode 中,这种从用户视角看到的字符有一个术语,它叫做扩展字位簇 (extended grapheme cluster)。
如何用标量来形成字位簇的规则,将决定字符文本是如何分段的。比如说,让你敲击键盘上的退格键时,你期望的是文本编辑器删除掉一个字位簇。这个“字符”有可能是由多个 Unicode 标量组成的,每个标量在文本表示的内存存储中,又可能使用了可变数量的编码单元。在 Swift 中,字位簇由 Character 类型进行表示,这个类型可以对任意数量的标量进行编码,并形成一个从用户角度来看的字符。我们很快就会在下面的部分看到这样的例子。
字位簇和标准等价
合并标记
一种快速考察 String 是如何处理 Unicode 数据的方法是研究 “é” 的两种不同写法。Unicode 将 U+00E9 (带尖音符的小写拉丁字母 e) 定义成一个单一值。不过你也可以用一个普通的字母 “e” 后面跟一个 U+0301 (组合尖音符) 来表达它。这两种写法都显示为 é,而且用户多半也对两个都显示为 “résumé” 的字符串彼此相等且含有六个字符有着合理的预期,而不管里面的两个 “é” 是由哪种方式生成的。Unicode 规范将此称作标准等价 (canonically equivalent)。
而这正是你将看到的 Swift 的运作方式:
let single = "Pok\u{00E9}mon" // Pokémon
let double = "Poke\u{0301}mon" // Pokémon
它们的显示一模一样:
(single, double) // ("Pokémon", "Pokémon")
并且两者有着相等的字符数:
single.count // 7
double.count // 7
而且,对它们进行比较,结果也是相同:
single == double // true
只有当你深入察看其底层形态时才能发现它们的不同:
single.utf16.count // 7
double.utf16.count // 8
将它和 Foundation 中的 NSString 对照:两个字符串并不相等,并且 length 属性 (许多程序员大概会用此属性计算显示在屏幕上的字符数) 给出了不同的结果:
let nssingle = single as NSString
nssingle.length // 7
let nsdouble = double as NSString
nsdouble.length // 8
nssingle == nsdouble // false
这里 == 被定义成比较两个 NSObject 的版本:
extension NSObject: Equatable {
static func ==(lhs: NSObject, rhs: NSObject) -> Bool {
return lhs.isEqual(rhs)
}
}
就 NSString 而言,这会在 UTF-16 编码单元的层面上,按字面值做一次比较,而不会将不同字符组合起来的等价性纳入考虑。其他语言的大部分字符串 API 也都是这么做的。如果你真要进行标准的比较,你必须使用 NSString.compare(_:)。你不知道这点?将来那些难以追查的 bug 和暴脾气的国际用户们可够你喝一壶的了。
当然,只比较编码单元有一个很大的好处:它更快!Swift 的字符串通过 utf16 的表示方式也能达成这个效果:
single.utf16.elementsEqual(double.utf16) // false
到底是为什么 Unicode 需要支持对同一个字符进行多种表示?预组合字符的存在使得开放区间的 Unicode 编码点可以和拥有 “é” 和 “ñ” 这类字符的 Latin-1 兼容。这使得两者之间的转换快速而简单,尽管处理它们还是挺痛苦的。
抛弃这种组合的形式也不会有帮助,因为字符的组合并不只有成对的情况;你可以把一个以上的变音符号组合在一起。比如约鲁巴语有一个字符,可以用三种不同的形式来书写:通过组合 ó 和一个点;通过组合 ọ 和一个尖音符;或者是通过组合 o 和一个点与一个尖音符。而对于最后这种形式,两个变音符号的顺序甚至可以调换!所以下面这些全是相等的:
let chars: [Character] = [
"\u{1ECD}\u{300}", // ọ́
"\u{F2}\u{323}", // ọ́
"\u{6F}\u{323}\u{300}", // ọ́
"\u{6F}\u{300}\u{323}" // ọ́
]
let allEqual = chars.dropFirst().all { $0 == chars.first } // true
(all(matching:) 方法对序列中的所有元素进行条件检查,判断是否为真。此方法的定义见内建集合。)
实际上,某些变音符号可以被无限地添加:
let zalgo = "s̼̐͗͜o̠̦̤ͯͥ̒ͫ́ͅo̺̪͖̗̽ͩ̃͟ͅn̢͔͖͇͇͉̫̰ͪ͑"
zalgo.count // 4
zalgo.utf16.count // 36
在上面,zalgo.count 返回 4,而 zalgo.utf16.count 返回 36。 如果你的代码不能正确处理这些网红字符,那还有什么用呢?
就算你要处理的所有字符串都是纯 ASCII 的,Unicode 的字位分隔规则还是会产生影响:CR+LF 字符表示回车 (carriage return) 和换行 (line feed) 的组合,它在 Windows 系统上通常被当作换行来使用,其实它是单个的字位簇:
// CR+LF 是单个字符
let crlf = "\r\n"
crlf.count // 1
颜文字
在很多其他语言中,含有颜文字的字符串也令人有些惊讶。很多颜文字是由无法存放在单个 UTF-16 编码单元的 Unicode 标量来表示的,比如在 Java 或者 C# 里,会认为 "😂" 是两个“字符”长。Swift 则能正确处理这种情况:
let oneEmoji = "😂" // U+1F602
oneEmoji.count // 1
注意这里重要的是,字符串是如何呈现在程序中的,而不是它是如何存储在内存中的。Swift 也使用了 UTF-16 在内部作为非 ASCII 字符串的编码方式,但是这都是实现细节。公有的 API 是基于字位簇的。
其他一些颜文字可能有多个标量组成,一个颜文字的国旗是由两个代表 ISO 国家码的区域表示字母所组成的。Swift 也能将它们正确地识别为一个 Character:
let flags = "🇧🇷🇳🇿"
flags.count // 2
要观察组成组成字符串的 Unicode 标量,我们可以使用字符串的 unicodeScalars 视图。这里,我们将标量值格式化为编码点常用的十六进制格式:
flags.unicodeScalars.map {
"U+\(String($0.value, radix: 16, uppercase: true))"
}
// ["U+1F1E7", "U+1F1F7", "U+1F1F3", "U+1F1FF"]
把五种肤色修饰符 (比如 🏽,或者其他四种肤色修饰符之一) 和一个像是 👧 的基础角色组合起来,就可以得到类似 👧🏽 这样的带有肤色的角色。再一次,Swift 能正确对其处理:
let skinTone = "👧🏽" // 👧 + 🏽
skinTone.count // 1
这次,让我们用 Foundation 的 API 进行 ICU 字符串变形,这可以将 Unicode 标量转换为它们对应的官方 Unicode 名字:
extension StringTransform {
static let toUnicodeName = StringTransform(rawValue: "Any-Name")
}
extension Unicode.Scalar {
/// 标量的 Unicode 名字,比如 "LATIN CAPITAL LETTER A".
var unicodeName: String {
// 强制解包是安全的,因为这个变形不可能失败
let name = String(self).applyingTransform(.toUnicodeName, reverse: false)!
// 变形后的字符串以 "\\N{...}" 作为名字开头,将它们去掉。
let prefixPattern = "\\N{"
let suffixPattern = "}"
let prefixLength = name.hasPrefix(prefixPattern) ? prefixPattern.count : 0
let suffixLength = name.hasSuffix(suffixPattern) ? suffixPattern.count : 0
return String(name.dropFirst(prefixLength).dropLast(suffixLength))
}
}
skinTone.unicodeScalars.map { $0.unicodeName }
// ["GIRL", "EMOJI MODIFIER FITZPATRICK TYPE-4"]
这段代码的核心部分是 applyingTransform(.toUnicodeName, …) 调用。剩下的代码对返回的名字进行了一些处理,去掉了两边的括号。我们采取了保守的做法来完成去除括号的操作:首先我们检查字符串是否匹配给定的表达式,然后计算需要从开头和结尾删除的字符数。如果今后这个变形方法返回的格式发生了不可预期的改变,我们最好是将整个字符串原封不动地返回。我们使用了 Collection 中标准的 dropFirst 和 dropLast 方法来进行删除操作。这是在不进行手动索引计算的前提下操作字符串的一个好例子。由于 dropFirst 和 dropLast 返回的是一个 Substring,它只是对原字符串的切片,所以这个操作也相当高效。直到最后我们从子字符串创建一个新的 String 之前,都不需要发生新的内存分配。我们会在本章稍后再对子字符串进行更多说明。
颜文字还可以描述家庭和情侣,比如 👨👩👧👦 和 👩❤️👩,,给 Unicode 标准正文带来了另外的挑战。由于在一组人的性别和人数上有无数可能的组合,为每一种组合提供一个独立的编码点是不太可行的。如果再考虑为每一个人添加肤色的话,这直接就不可能了。Unicode 通过将这些颜文字设定为实际含有多个颜文字的序列,来解决这个问题。这些序列中的颜文字将由不可见的零宽度连接符 (zero-width joiner,ZWJ) (U+200D) 所连接组合。所以,家庭颜文字 👨👩👧👦 实际上是由男人 👨 + ZWJ + 女人 👩 + ZWJ + 女孩 👧 + ZWJ + 男孩 👦 而构成的。ZWJ 的存在,是对操作系统的提示,表明如果可能的话,应该用单个的字符来进行表示。
你可以对这个颜文字进行验证:
let family1 = "👨👩👧👦"
let family2 = "👨\u{200D}👩\u{200D}👧\u{200D}👦"
family1 == family2 // true
再一次,Swift 非常聪明,它能把这样的序列识别为单个 Character:
family1.count // 1
family2.count // 1
在 2016 年引入的代表职业的颜文字也是 ZWJ 序列。比如,一个女性消防员 👩🚒 是女人 👩 + ZWJ + 消防车 🚒, 的组合。而男性医护工作者 👨⚕️ 则是男人 👨 + ZWJ + 医疗之神阿斯克勒庇俄斯的权杖 ⚕ 的序列。
将这些序列渲染为单个字形,是操作系统的任务。在 2017 年的 Apple 平台上,操作系统所包括的字形是 Unicode 标准所列出的一般交换所推荐支持的的序列 (RGI) 的子集。换句话说,这个列表中的颜文字“可以被认为是在多个平台被广泛支持的”。当对于一个语法上有效的序列,系统中没有对应可用的字形时,系统的字符渲染系统将会进行回退,将其中每个部分渲染为单独的字形。这样一来,用户视角的字符数和 Swift 所看到的单个字位簇就可能“在另一个方向上”发生不匹配了;到目前为止的的例子都是编程语言认为字符数较实际要多,而现在我们就会看到相反的情况。比如,带有肤色的家庭颜文字序列现在并不在 RGI 子集里。但是虽然操作系统会将它渲染为多个字形,Swift 依然将它算作单个的 Character,因为 Unicode 的文本分段规则并没有将渲染的问题考虑进去:
// 在 2017 年,带有肤色的家庭颜文字在大多数平台上会被渲染为多个字形
let family3 = "👱🏾\u{200D}👩🏽\u{200D}👧🏿\u{200D}👦🏻"
// 但是 Swift 依然认为它是单个字符
family3.count // 1
微软现在已经能够将上述带有肤色的家庭,以及一些其他变形渲染为单个字形了,而且其他的操作系统提供商应该肯定会马上跟进。但是事实就是,不论一个字符串 API 被如何精心设计,文本问题实在是太过复杂,永远都会有没有注意到的边界情况存在。
在过去,Swift 在跟随 Unicode 变化上遇到过一些困难。Swift 3 的时候对肤色和 ZWJ 序列的处理是不正确的,因为当时的算法是基于旧版本的 Unicode 标准的。从 Swift 4 开始,Swift 将使用系统的 ICU 库。这样一来,只要你的用户升级了它们的系统,你的程序就将自动适配新的 Unicode 规则。不过,这枚硬币的另一面就是,你不能保证用户所看到的和你在开发中所看到东西一定是完全一致的。
在本节中我们讨论的例子里,对于语言没有完全考虑 Unicode 的复杂性的情况,我们只用了字符串长度是否正确作为窗口来进行研究。随便想一想,要是一门编程语言在字符串中包含字符序列时,没有按照字位簇来处理字符串的话,像是翻转字符串这样操作,都会带来奇怪的结果。这并不是一个新问题,就算你的用户主要都使用英文,但随着颜文字爆炸性地流行,不严谨的文本处理所造成的诸多问题还是迅速浮上台面。另外,错误的幅度也日益增加,在以前,一个变音符号所带来的错误可能只是误差一个字符,但是现代颜文字通常会带来十个或更多的“字符”。比如,一个四人家庭颜文字在 UTF 16 中有 11 个编码单元长,而在 UTF-8 中这个数字则达到了 25:
family1.count // 1
family1.utf16.count // 11
family1.utf8.count // 25
并不是说其他语言就完全没有 Unicode 正确的 API,大部分其实都有。比如,NSString 有一个 enumerateSubstrings 方法,能被用来以字位簇的方式枚举字符串。但是默认行为十分重要,Swift 认为默认情况下行为正确具有更高的优先级。如果你想要下降到一个更低层级的抽象中,String 也提供了直接操作 Unicode 标量和编码单元的字符串视图。我们会在下面对它们进行更多讨论。
字符串和集合
我们已经提到过,String 是 Character 值的集合。在 Swift 存在的头三年里,String 在满足 Collection 协议和不满足 Collection 协议之间来回摇摆了几次。不添加 Collection 的观点认为,如果支持了 Collection,开发者会认为所有一般化的集合处理算法在处理字符串时也是绝对安全和 Unicode 正确的,而这在某些边界情况下并非事实。
举个简单的例子,在将两个集合连接的时候,你可能会假设所得到的集合的长度是两个用来连接的集合长度之和。但是对于字符串来说,如果第一个集合的末尾和第二个集合的开头能够形成一个字位簇的话,它们就不再相等:
let flagLetterC = "🇨"
let flagLetterN = "🇳"
let flag = flagLetterC + flagLetterN // 🇨🇳
flag.count // 1
flag.count == flagLetterC.count + flagLetterN.count // false
考虑到这一点,在 Swift 2 和 Swift 3 中 String 本身并非 Collection。由字符组成的集合被移动到了 characters 属性里,它和 unicodeScalars,utf8 以及 utf16 等其他集合视图类似,是一种字符串的表现形式。选取某一个特定的字符串视图可以提醒你进入了“集合处理”的模式,你需要自行考虑这对即将运行的算法会有什么影响。
在实践中,这个改动带来的易用性上的损失和学习难度的增加,相对于在实际代码中 (除非你在写一款文本编辑器) 带来的非常稀有的边界情况下的正确性的提升,实在是得不偿失。所以在 Swift 4 里,String 又成为了 Collection。characters 视图依然存在,但是仅仅是为了代码的前向兼容。
双向索引,而非随机访问
不过,在上面的例子中需要特别澄清的是,String 并不是一个可以随机访问的集合。就算知道给定字符串中第 n 个字符的位置,也并不会对计算这个字符之前有多少个 Unicode 标量有任何帮助。所以,String 只实现了 BidirectionalCollection。你可以从字符串的头或者尾开始,向后或者向前移动,代码会察看毗邻字符的组合,跳过正确的字节数。不管怎样,你每次只能迭代一个字符。
当你在书写一些字符串处理的代码时,需要将这个性能影响时刻牢记在心。那些需要随机访问才能维持其性能保证的算法对于 Unicode 字符串来说并不是一个好的选择。假设我们要扩展 String,来生成一个包含字符串所有前缀子字符串的数组。我们可以先生成从 0 开始到字符串长度的范围,然后对这个范围进行映射,来为每个长度值创建前缀字符串:
extension String {
var allPrefixes1: [Substring] {
return (0...self.count).map(self.prefix)
}
}
let hello = "Hello"
hello.allPrefixes1 // ["", "H", "He", "Hel", "Hell", "Hello"]
这段代码看上去简单,但是它非常低效。首先,它会遍历一次字符串,来计算其长度,这没什么大问题。但是,之后 n + 1 次对 prefix 的调用中,每一次都是一个 O(n) 操作,这是因为 prefix 总是要从头开始工作,然后在字符串上经过所需要的字符个数。在一个线性复杂度的处理中运行另一个线性复杂度的操作,意味着算法复杂度将会是 O(n2)。随着字符串长度的增长,这个算法所花费的时间将以平方的方式增加。
如果可能的话,一个高效的字符串算法应该只对字符串进行一次遍历,而且它应该操作字符串的索引,用索引来表示感兴趣的子字符串。这里是相同算法的另一个版本:
extension String {
var allPrefixes2: [Substring] {
return [""] + self.indices.map { index in self[...index] }
}
}
hello.allPrefixes2 // ["", "H", "He", "Hel", "Hell", "Hello"]
上面的代码依然需要迭代一次字符串,以获取索引的集合 indices。不过,一旦这个过程完成,map 中的下标操作就是 O(1) 复杂度的。这使得整个算法的复杂度得以保持在 O(n)。
我们在集合类型协议一章中实现的
PrefixIterator以泛型的方式为所有序列解决了相同的问题。
范围可替换,而非可变
String 还满足 RangeReplaceableCollection 协议。下面的例子中,展示了如何首先找到字符串索引中一个恰当的范围,然后通过调用 replaceSubrange 来完成字符串替换。用于替换的字符串可以有不同的长度,或者甚至可以是一个空字符串 (这时相当于调用了 removeSubrange):
var greeting = "Hello, world!"
if let comma = greeting.index(of: ",") {
greeting[..<comma] // Hello
greeting.replaceSubrange(comma..., with: " again.")
}
greeting // Hello again.
和之前一样,要注意用于替换的字符串有可能与原字符串相邻的字符形成新的字位簇。
MutableCollection 是一个集合的经典特性,然而字符串并没有实现这个协议。MutableCollection 协议为集合添加的是除开 get 以外的对单个元素进行 set 的下标方法。这并不是说字符串是不可变的,我们刚才已经看到过,字符串拥有一系列可变方法。但是你无法做到通过下标操作对一个字符进行替换。究其原因,又回到可变长度的字符上。大部分人直觉上会认为,就像在 Array 中那样,单个元素的下标更新会在常数时间内完成。但是由于字符串中的字符可能是可变长度,改变其中一个元素的宽度将意味着要把后面元素在内存中的位置上下移动。不止如此,在被插入的索引位置之后的所有索引值也会由于内存未知的改动而失效,这同样并不直观。由于这些原因,就算你想要更改的元素只有一个,你也必须使用 replaceSubrange。
字符串索引
大部分编程语言使用整数值对字符串进行下标操作,比如 str[5] 将会返回 str 中的第六个“字符” (这里的“字符”的概念由所操作的编程语言进行定义)。Swift 不允许这么做。为什么?答案可能现在你已经很耳熟了:因为整数的下标访问无法在常数时间内完成 (对于 Collection 协议来说这也是个直观要求),而且查找第 n 个 Character 的操作也必须要对它之前的所有字节进行检查。
String.Index 是 String 和它的视图所使用的索引类型,它本质上是一个存储了从字符串开头的字节偏移量的不透明值。如果你想计算第 n 个字符所对应的索引,你依然从字符串的开头或结尾开始,并花费 O(n) 的时间。但是一旦你拥有了有效的索引,就可以通过索引下标以 O(1) 的时间对字符串进行访问了。至关重要的是,通过一个已有索引来寻找下一个索引也是很快的,因为你可以从这个已有索引的字节偏移量开始进行查找,而不需要从头开始。正是由于这个原因,按顺序 (前向或者后向) 对字符串中的字符进行迭代是一个高效操作。
对字符串索引的操作的 API 与你在遇到其他任何集合时使用的索引操作是一样的。我们之所以经常容易忽略索引操作的等效性,是因为到现在为止我们最经常使用的数组的索引是整数类型,于是我们往往通过简单的算数,而非正式的索引操作 API,来对数组索引进行操作。index(after:) 方法将返回下一个字符的索引:
let s = "abcdef"
let second = s.index(after: s.startIndex)
s[second] // b
你可以通过 index(_:offsetBy:) 方法来一次性地自动对多个字符进行迭代:
// 步进 4 个字符
let sixth = s.index(second, offsetBy: 4)
s[sixth] // f
如果存在超过字符串末尾的风险,你可以加上 limitedBy: 参数。如果这个方法在达到目标索引之前就先触发了限制条件的话,它将返回 nil:
let safeIdx = s.index(s.startIndex, offsetBy: 400, limitedBy: s.endIndex)
safeIdx // nil
毫无疑问,这比简单的整数索引需要更多的代码,但是再一次,Swift 就是这样设计的。如果 Swift 允许使用整数下标索引来访问字符串,会大大增加意外地写出性能相当糟糕的代码的可能性 (比如,在一个循环中使用了整数下标)。
确实,对习惯于处理固定长度字符的人来说,起初操作 Swift 字符串看上去颇具挑战性。不通过整数索引你要怎么浏览字符呢?确实,很多看起来很简单的任务,比如说要提取字符串的前四个字符,实现看起来都会有些奇怪:
s[..<s.index(s.startIndex, offsetBy: 4)] // abcd
不过令人欣慰的是,我们可以通过 Collection 的接口来访问字符串,也就是说你能按照需求使用很多有用的技术。许多操作 Array 的函数一样可以操作 String。使用 prefix 方法,同样的事情就清楚多了:
s.prefix(4) // abcd
(注意,两个表达式返回的都是 Substring;你可以通过将其传递给 String.init 将它转换回 String。我们会在下一节里再谈到子字符串的话题。)
不使用整数索引就可以很容易地遍历字符串中的字符,你只需要用一个 for 循环就行了。如果你还需要每个字符的序号,可以使用 enumerated:
for (i, c) in "hello".enumerated() {
print("\(i): \(c)")
}
或许你要找到某个特定的字符。这种情况你可以用 index(of:):
var hello = "Hello!"
if let idx = hello.index(of: "!") {
hello.insert(contentsOf: ", world", at: idx)
}
hello // Hello, world!
insert(contentsOf:) 方法将会把另一个具有相同元素类型 (对于字符串来说就是 Character) 的集合插入到给定索引之后。这个集合并不需要是另一个 String,你也可以很容易地将一个字符组成的数组插入到字符串中。
子字符串
和所有集合类型一样,String 有一个特定的 SubSequence 类型,它就是 Substring。Substring 和 ArraySlice 很相似:它是一个以不同起始和结束索引的对原字符串的切片。子字符串和原字符串共享文本存储,这带来的巨大的好处,它让对字符串切片成为了非常高效的操作。在下面的例子中,创建 firstWord 并不会导致昂贵的复制操作或者内存申请:
let sentence = "The quick brown fox jumped over the lazy dog."
let firstSpace = sentence.index(of: " ") ?? sentence.endIndex
let firstWord = sentence[..<firstSpace] // The
type(of: firstWord) // Substring
在你对一个 (可能会很长的) 字符串进行迭代并提取它的各个部分的循环中,切片的高效特性就非常重要了。这类任务可能包括在文本中寻找某个单词出现的所有位置,或者解析一个 CSV 文件等。在这里,字符串分割是一个很有用的操作。Colleciton 定义了一个 split 方法,它会返回一个子序列的数组 (也就是 [Substring])。最常用的一种形式是:
extension Collection where Element: Equatable {
public func split(separator: Element, maxSplits: Int = Int.max,
omittingEmptySubsequences: Bool = true) -> [SubSequence]
}
你可以这样来使用:
let poem = """
Over the wintry
forest, winds howl in rage
with no leaves to blow.
"""
let lines = poem.split(separator: "\n")
// ["Over the wintry", "forest, winds howl in rage", "with no leaves to blow."]
type(of: lines) // Array<Substring>
这个函数和 String 从 NSString 继承来的 components(separatedBy:) 很类似,不过还多加了一个决定是否要丢弃空值的选项。再一次,整个过程中没有发生对输入字符串的复制。因为 split 还有一种形式可以接受闭包作为参数,所以除了单纯的字符比较以外,它还能做更多的事情。这里有一个简单的按词折行算法的例子,其中闭包里捕获了当前行中的字符数:
extension String {
func wrapped(after: Int = 70) -> String {
var i = 0
let lines = self.split(omittingEmptySubsequences: false) {
character in
switch character {
case "\n", " " where i >= after:
i = 0
return true
default:
i += 1
return false
}
}
return lines.joined(separator: "\n")
}
}
sentence.wrapped(after: 15)
/*
The quick brown
fox jumped over
the lazy dog.
*/
又或者,考虑写一个接受含有多个分隔符的序列作为参数的版本:
extension Collection where Element: Equatable {
func split<S: Sequence>(separators: S) -> [SubSequence]
where Element == S.Element
{
return split { separators.contains($0) }
}
}
现在,你就可以写出下列语句了:
"Hello, world!".split(separators: ",! ") // ["Hello", "world"]
StringProtocol
Substring 和 String 的接口几乎完全一样。这是通过一个叫做 StringProtocol 的通用协议来达到的,String 和 Substring 都遵守这个协议。因为几乎所有的字符串 API 都被定义在 StringProtocol 上,对于 Substring,你完全可以假装将它看作就是一个 String,并完成各项操作。不过,在某些时候,你还是需要将子字符串转回 String 实例;和所有的切片一样,子字符串也只能用于短期的存储,这可以避免在操作过程中发生昂贵的复制。当这个操作结束,你想将结果保存起来,或是传递给下一个子系统,这时你应该通过初始化方法从 Substring 创建一个新的 String,如下例所示:
func lastWord(in input: String) -> String? {
// 处理输入,操作子字符串
let words = input.split(separators: [",", " "])
guard let lastWord = words.last else { return nil }
// 转换为字符串并返回
return String(lastWord)
}
lastWord(in: "one, two, three, four, five") // Optional("five")
不鼓励长期存储子字符串的根本原因在于,子字符串会一直持有整个原始字符串。如果有一个巨大的字符串,它的一个只表示单个字符的子字符串将会在内存中持有整个字符串。即使当原字符串的生命周期本应该结束时,只要子字符串还存在,这部分内存就无法释放。长期存储子字符串实际上会造成内存泄漏,由于原字符串还必须被持有在内存中,但是它们却不能再被访问。
通过在一个操作内部使用子字符串,而只在结束时创建新字符串,我们将复制操作推迟到最后一刻,这可以保证由这些复制操作所带来的开销是实际需要的。在上面的例子中,我们将这个 (可能很长) 的字符串分割为子字符串,但是付出的开销只是在最后复制了一个短的子字符串。(虽然算法本身不够高效,但我们现在先忽略这块;从后向前进行迭代,直到我们找到第一个分隔符,会是更好的策略。)
接受 Substring 的函数非常罕见,大多数的函数要么接受 String,要么接受任意满足 StringProtocol 协议的类型。但是如果你确实需要传递 Substring 的话,最快的方式是用不指定任何边界的范围操作符 ... 通过下标方式访问字符串:
// 使用原字符串开头索引和结尾索引作为范围的子字符串
let substring = sentence[...]
我们已经在集合类型协议一章中定义 Words 集合的时候看到过这样的例子了。
Substring类型是 Swift 4 中新加入的。在 Swift 3 里,String.CharacterView的切片类型就是它自身。这么做的好处是用户只需要理解一个类型就行了,不过这也意味着被存储的子字符串会需要持有整个原字符串的内存,即使原字符串应该已经被释放的情况下依旧如此。Swift 4 通过损失一小部分易用性来获取高效的切片操作和可预测的内存使用。Swift 团队也意识到了要求显式地将
Substring转换为String有一点烦人。如果在实际使用中这个转换成为大麻烦的话,开发团队也在考虑在编译器中为Substring和String加入隐式的子类型关系,就像Int是Optional<Int>的一个子类型那样。这可以让你直接将Substring传递给原本只接受String的地方,编辑器会为你执行这个转换。
你可能会经不住 StringProtocol 存在的种种优点的诱惑,将你的所有 API 从接受 String 实例转换为 StringProtocol。但是 Swift 团队给我们的建议是不要这么做。
一般来说,我们的建议是坚持使用
String。在大部分 API 中只使用String,而不是将它换为泛型 (其实泛型本身也会带来开销),会更加简单和清晰。用户在有限的几个场合对String进行转换,这不会带来太大的负担。
那些及有可能使用到子字符串,同时也没有更进一步泛型化到 Sequence 或者 Collection 这样层级的 API,不适用于这条规则。标准库中的 joined 方法就是这样的例子。Swift 4 为元素满足 StringProtocol 的序列添加了一个 joined 的重载方法:
extension Sequence where Element: StringProtocol {
/// 将一个序列中的元素使用给定的分隔符拼接起为新的字符串,并返回
public func joined(separator: String = "") -> String
}
这让你可以直接在 (比如可能通过 split 得到的) 子字符串的数组上调用 joined,而不需要对这个数组进行 map 操作将每个子字符串转换为一个新的字符串。这要方便很多,而且也快很多。
那些接受字符串并将它们转换为数字的数字类型初始化方法在 Swift 4 中也接受 StringProtocol。同样,这在你想要处理一个子字符串数组中会特别有用:
let commaSeparatedNumbers = "1,2,3,4,5"
let numbers = commaSeparatedNumbers
.split(separator: ",").flatMap { Int($0) }
// [1, 2, 3, 4, 5]
因为子字符串应当是短时存在的,所以除非是那些 Sequence 或 Collection 的返回切片的 API,否则一般不建议一个函数返回子字符串。如果你正在写一个只对字符串有效的类似的函数的话,返回子字符串就意味着告诉读者没有发生复制。像是 uppercased() 这样包含内存申请以及创建新的字符串函数,应该总是返回 String。
如果你想要扩展 String 为其添加新的功能,将这个扩展放在 StringProtocol 会是一个好主意,这可以保持 String 和 Substring API 的统一性。StringProtocol 设计之初就是为了在你想要对 String 扩展时来使用的。如果你想要将已有的扩展从 String 移动到 StringProtocol 的话,唯一需要做的改动是将传入其他 API 的 self 通过 String(self) 换为具体的 String 类型实例。
不过需要记住,在 Swift 4 中,StringProtocol 还并不是一个你想要构建自己的字符串类型时所应该实现的目标协议。文档中明确警告了这一点:
不要声明任意新的遵守
StringProtocol协议的类型。只有标准库中的String和Substring类型是有效的适配类型。
最终的目标是允许开发者创建他们自己的字符串类型 (比如带有特定的存储或者性能优化),但是协议的设计还没有结束,所以现在就遵守这个协议的话,可能会让你的代码在 Swift 5 中无法通过编译。
编码单元视图
字符串和 Foundation
String 和 Character 的内部结构
简单的正则表达式匹配器
ExpressibleByStringLiteral
CustomStringConvertible 和 CustomDebugStringConvertible
文本输出流
字符串性能
回顾
错误处理
Swift 提供了很多种处理错误的方式,它甚至允许我们创建自己的错误处理机制。在可选值中,我们看到过可选值和断言 (assertions) 的方法。可选值意味着一个值可能存在,也可能不存在。我们在实际使用这个值之前,必须先对其确认并解包。断言会验证条件是否为 true,如果条件不满足的话,程序将会崩溃。
如果我们仔细看看标准库中类型的接口的话,我们可以得到一个何时应该使用可选值,而何时不应该使用的大概印象。可选值被广泛用来代表那些可以清楚地表明“不存在”或者“无效输入”的情况。比如说,你在使用一个字符串初始化 Int 时的初始化方法就是可失败的,如果输入不是有效的整数数字字符串,结果就将是 nil。另一个例子是当你在字典里查找一个键时,很多时候这个键并不存在于字典中。因此,字典的查找返回的是一个可选值结果。
对比数组,当通过一个指定的索引获取数组元素时,Swift 会直接返回这个元素,而不是一个包装后的可选值。这是因为一般来说程序员都应该知道某个数组索引是否有效。通过一个超出边界的索引值来访问数组通常被认为是程序员的错误,而这也会让你的应用崩溃。如果你不确定一个索引是否在某个范围内,你应该先对它进行检查。
断言是定位你代码中的 bug 的很好的工具。使用得当的话,它可以在你的程序偏离预定状态的时候尽早对你作出提醒。它们不应该被用来标记像是网络错误那样的预期中的错误。
注意数组其实也有返回可选值的访问方式。比如 Collection 的 first 和 last 属性就将在集合为空的时候返回 nil。Swift 标准库的开发者是有意进行这样的设计的,因为当集合可能为空时还需要访问这些值的情况还是比较容易出现的。
除了从方法中返回一个可选值以外,我们还可以通过将函数标记为 throws 来表示可能会出现失败的情况。除了调用者必须处理成功和失败的情况的语法以外,和可选值相比,能抛出异常的方法的主要区别在于,它可以给出一个包含所发生的错误的详细信息的值。
这个区别决定了我们要使用哪种方法来表示错误。回顾下 Collection 的 first 和 last,它们只可能有一种错误的情况,那就是集合为空时。返回一个包含很多信息的错误并不会让调用者获得更多的情报,因为错误的原因已经在可选值中表现了。对比执行网络请求的函数,情况就不一样了。在网络请求中,有很多事情可能会发生错误,比如当前没有网络连接,或者无法解析服务器的返回等等。带有信息的错误在这种情况下就对调用者非常有用了,它们可以根据错误的不同来采取不同的对应方法,或者可以提示用户到底哪里发生了问题。
Result 类型
抛出和捕获
带有类型的错误
将错误桥接到 Objective-C
错误和函数参数
使用 defer 进行清理
错误和可选值
错误链
高阶函数和错误
回顾
泛型
和大多数先进语言一样,Swift 拥有不少能被归类于泛型编程下的特性。使用泛型代码,你可以写出可重用的函数和数据结构,只要它们满足你所定义的约束,它们就能够适用于各种类型。比如,像是 Array 和 Set 等多个类型,实际上是它们中的元素类型就是泛型抽象。我们也可以创建泛型方法,它们可以对输入或者输出的类型进行泛型处理。func identity<A>(input: A) -> A 就定义了一个可以作用于任意类型 A 的函数。某种意义上,我们甚至可以认为带有关联类型的协议是“泛型协议”。关联类型允许我们对特定的实现进行抽象。IteratorProtocol 协议就是一个这样的例子:它所生成的 Element 就是一个泛型。
泛型编程的目的是表达算法或者数据结构所要求的核心接口。比如,考虑内建集合一章中的 last(where:) 函数。将它写为 Array 的一个扩展原本是最明显的选择,但是 Array 其实包含了很多 last(where:) 并不需要的特性。通过确认核心接口到底是什么,也就是说,找到想要实现的功能的最小需求,我们可以将这个函数定义在宽阔得多的类型范围内。在这个例子中,last(where:) 只有一个需求:它需要能够逆序遍历一系列元素。所以,将这个算法定义为 Sequence 的扩展是更好的选择 (我们也可以为 BidirectionalCollection 添加一个更高效的实现)。
在本章中,我们会研究如何书写泛型代码。我们会先看一看什么是重载 (overloading) ,因为这个概念和泛型紧密相关。然后我们会使用泛型的方式,基于不同的假设,来为一个算法提供多种实现。之后我们将讨论一些你在为集合书写泛型算法时会遇到的常见问题,了解这些问题后你就将能使用泛型数据类型来重构代码,并使它们易于测试,更加灵活。最后,我们会谈一谈编译器是如何处理泛型代码的,以及要如何优化我们的泛型代码以获取更高性能的问题。
重载
拥有同样名字,但是参数或返回类型不同的多个方法互相称为重载方法,方法的重载并不意味着泛型。不过和泛型类似,我们可以将多种类型使用在同一个接口上。
自由函数的重载
我们可以定义一个名字为 raise(_:to:) 的函数,它可以通过针对 Double 和 Float 参数的不同重载来分别执行幂运算操作:
对集合采用泛型操作
使用泛型进行代码设计
泛型的工作方式
回顾
协议
在上一章,我们看到了函数和泛型可以帮助我们写出动态的程序。协议可以与函数和泛型协同工作,让我们代码的动态特性更加强大。
Swift 的协议和 Objective-C 的协议不同。Swift 协议可以被用作代理,也可以让你对接口进行抽象 (比如 IteratorProtocol 和 Sequence)。它们和 Objective-C 协议的最大不同在于我们可以让结构体和枚举类型满足协议。除此之外,Swift 协议还可以有关联类型。我们还可以通过协议扩展的方式为协议添加方法实现。我们会在面向协议编程的部分讨论所有这些内容。
协议允许我们进行动态派发,也就是说,在运行时程序会根据消息接收者的类型去选择正确的方法实现。不过,方法到底什么时候是动态派发,什么时候不是动态派发,有时却不是那么直观,并有可能造成令人意外的结果。我们会在下一节中看到这个问题。
普通的协议可以被当作类型约束使用,也可以当作独立的类型使用。带有关联类型或者 Self 约束的协议特殊一些:我们不能将它当作独立的类型来使用,所以像是 let x: Equatable 这样的写法是不被允许的;它们只能用作类型约束,比如 func f<T: Equatable>(x: T)。这听起来似乎是一个小限制,但是这在实践中让带有关联类型的协议成为了完全不同的东西。我们会在之后详细对此说明,我们还将讨论如何使用 (像是 AnyIterator 这样的) 类型消除的方法来让带有关联类型的协议更加易用。
在面向对象编程中,子类是在多个类之间共享代码的有效方式。一个子类将从它的父类继承所有的方法,然后选择重写其中的某些方法。比如,我们可以有一个 AbstractSequence 类,以及像是 Array 和 Dictionary 这样的子类。这么做的话,我们就可以在 AbstractSequence 中添加方法,所有的子类都将自动继承到这些方法。
不过在 Swift 中,Sequence 中的代码共享是通过协议和协议扩展来实现的。通过这么做,Sequence 协议和它的扩展在结构体和枚举这样的值类型中依然可用,而这些值类型是不支持子类继承的。
不再依赖于子类让类型系统更加灵活。在 Swift (以及其他大多数面向对象的语言) 中,一个类只能有一个父类。当我们创建一个类时,我们必须同时选择父类,而且我们只能选择一个父类,我们无法创建比如同时继承了 AbstractSequence 和 Stream 的类。这有时候会成为问题。在 Cocoa 中就有一些例子,比如 NSMutableAttributedString,框架的设计师必须在 NSAttributedString 和 NSMutableString 之间选择一个父类。
有一些语言有多继承的特性,其中最常见的是 C++。但是这也导致了钻石问题 (或者叫菱型缺陷) 的麻烦。举例来说,如果可以多继承,那么我们就可以让 NSMutableAttributedString 同时继承 NSMutableString 和 NSAttributedString。但是要是这两个类中都重写了 NSString 中的某个方法的时候,该怎么办?你可以通过选择其中一个方法来解决这个问题。但是要是这个方式是 isEqual: 这样的通用方法又该怎么处理呢?实际上,为多继承的类提供合适的行为真的是一件非常困难的事情。
因为多继承如此艰深难懂,所以绝大多数语言都不支持它。不过很多语言支持实现多个协议的特性。相比多继承,实现多个协议并没有那些问题。在 Swift 中,编译器会在方法冲突的时候警告我们。
协议扩展是一种可以在不共享基类的前提下共享代码的方法。协议定义了一组最小可行的方法集合,以供类型进行实现。而类型通过扩展的方式在这些最小方法上实现更多更复杂的特性。
比方说,要实现一个对任意序列进行排序的泛型算法,你需要两件事情。首先,你需要知道如何对要排序的元素进行迭代。其次,你需要能够比较这些元素的大小。就这么多。我们没有必要知道元素是如何被存储的,它们可以是在一个链表里,也可以在数组中,或者任何可以被迭代的容器中。我们也没有必要规定这些元素到底是什么,它们可以是字符串,整数,数据,或者是具体的像是“人”这样的数据类型。只要你在类型系统中提供了前面提到的那两个约束,我们就能实现 sort 函数:
extension Sequence where Element: Comparable {
func sorted() -> [Self.Element]
}
想要实现原地排序的话,我们需要更多的构建代码。你需要能够通过索引访问元素,而不仅仅是进行线性迭代。Collection 满足这点,而 MutableCollection 在其之上加入了可变特性。最后,你需要能在常数时间内比较索引,并移动它们。RandomAccessCollection 正是用来保证这一点的。这些听起来可能有点复杂,但这正是我们能够实现一个原地排序所需要的前置条件:
extension MutableCollection where
Self: RandomAccessCollection, Self.Element: Comparable {
mutating func sort()
}
通过协议来描述的最小功能可以很好地进行整合。你可以一点一点地为某个类型添加由不同协议所带来的不同功能。我们已经在集合协议这章中一开始使用单个 cons 方法构建 List 类型的例子中看到过这样的应用场景了。我们让 List 实现了 Sequence 协议,而没有改变原来 List 结构体的实现。实际上,即使我们不是这个类型的原作者,也可以使用追溯建模 (retroactive modeling) 的方式完成这件事情。通过添加 Sequence 的支持,我们直接获得了 Sequence 类型的所有扩展方法。
通过共同的父类来添加共享特性就没那么灵活了;在开发过程进行到一半的时候再决定为很多不同的类添加一个共同基类往往是很困难的。你想这么做的话,可能需要大量的重构。而且如果你不是这些子类的拥有者的话,你直接就无法这么处理!
子类必须知道哪些方法是它们能够重写而不会破坏父类行为的。比如,当一个方法被重写时,子类可能会需要在合适的时机调用父类的方法,这个时机可能是方法开头,也可能是中间某个地方,又或者是在方法最后。通常这个调用时机是不可预估和指定的。另外,如果重写了错误的方法,子类还可能破坏父类的行为,却不会收到任何来自编译器的警告。
面向协议编程
协议的两种类型
带有 Self 的协议
协议内幕
回顾
互用性
Swift 最大的一个优点是它在于 C 或者 Objective-C 混合使用时,阻力非常小。Swift 可以自动桥接 Objective-C 的类型,它甚至可以桥接很多 C 的类型。这让我们可以使用现有的代码库,并且在其基础上提供一个漂亮的 API 接口。
在本章中,我们将创建一个对 CommonMark 库的封装。CommonMark 是 Markdown 的一种正式规范。如果你曾经在 GitHub 或者 Stack Overflow 上写过东西的话,那你应该已经用过 Markdown 了,它是一种很流行的用纯文本进行格式化的语法。在这个实践例子之后,我们会研究一下标准库中所提供的操作内存的工具,以及我们如何使用它们来于 C 代码进行交互。
实践:封装 CommonMark
Swift 调用 C 代码的能力让我们可以很容易地使用大量已经存在的 C 的代码库。用 Swift 来对一个库的接口进行封装,一般来说要比重新发明轮子简单得多,工作量也少得多。同时,封装得当的话,我们的用户将不会看到这个封装和原生实现在类型安全以及易用性上有什么区别。我们只需要一个动态库和它的 C 语言头文件,就可以开始进行封装工作了。
我们的例子中会用到 C 语言的 CommonMark 库,它是一个 CommonMark 标准的参考实现,这个实现非常高效,而且测试也很齐全。我们采用层层递进的方式进行封装,让我们可以通过 Swift 访问它。首先,我们围绕库所暴露给外界的不透明类型 (opaque type) 来创建一个简易的 Swift 类。然后,我们会将这个类封装到 Swift enum 中,并提供更符合 Swift 风格的 API。
低层级类型概览
函数指针
回顾
写在最后
希望你能享受这段和我们一起的徜徉在 Swift 中的旅程。
虽然 Swift 还很年轻,但是它已经是一门复杂的语言了。想要在一本书里覆盖到它的方方面面,几乎是不可能的;而想让读者都能将它们记住,更是难上加难。
我们基于自己的兴趣,为本书选择了一些话题。除了官方的文档中提到的那些东西,我们还想知道什么?这些东西在底层是如何工作的?以及或许更重要的,为什么 Swift 会表现出某种行为?
即使你无法马上学以致用,我们也坚信,对你使用的语言的更深入理解可以让你成为更加优秀的程序员。
Swift 仍然在快速变化着。大规模源码级别型破坏的时代可能已经里我们远去,但是在今后几年中,我们依然期待在下面这些地方会有重大的增强:
Swift 5 的一个重大目标是达成 ABI (application binary interface) 稳定。它在很大程度上影响着像是内存结构和调用规范等内部细节。但是 ABI 稳定的一个重要前提是最终决定标准库的 API,这与每个人都息息相关。标准库能从泛型系统中获益,而 Swift 5 中一个主要的焦点就是如何对泛型系统进行进一步增强。
明确的内存所有权模型允许开发者将函数参数根据所有权的要求进行标注。这个增强的目标是,为编译器提供所有所需要的信息,让它可以在传递值时避免不必要的复制操作。Swift 4 中已经引入了编译时的强制独占内存访问,这是该增强的第一块拼图。
对在 Swift 中增加语言内建的并行支持的讨论才刚刚开始,这项工程可能需要花费数年才能完成。我们可能会在不远的将来,看到其他一些语言中大受欢迎的基于协程的
async/await特性被加入 Swift 中。
如果你对这些增强或者其他特性会对 Swift 造成怎样的影响感兴趣的话,不要忘了 Swift 的开发是开放的。你可以加入到 Swift 进化话题的邮件列表中,在那里参加讨论,并发表你的观点。
最后,我们想要鼓励你好好利用 Swift 开源这一优势。当你遇到问题,但是文档无法回答的时候,通常源码会为你提供答案。如果你已经看到这里了,相信你已经可以自己找到标准库的源码文件了。能够对事情是如何被实现的进行确认,在我们写作本书时,也起到了莫大的帮助。